Using AI assistant signals in B2B purchase funnel monitoring

The visibility gap: What today's B2B analytics fails to capture
The B2B buying process begins far earlier than any dashboard reveals. Before a potential customer lands on a website, fills out a contact form, or clicks an ad, they often spend hours researching - increasingly through AI assistants such as ChatGPT, Perplexity, or Gemini. This early research phase is completely invisible to traditional analytics tools.
Classic solutions - Google Analytics, CRM systems, marketing automation platforms - only start recording user behavior once someone reaches a company-controlled touchpoint. Everything that happens before that moment remains beyond the reach of measurement. The problem itself is not new: prospect research has always partially taken place outside a company's own ecosystem. What is new is the scale and the qualitative shift in how this happens. AI assistants can deliver a synthesized comparison of several competing solutions in seconds - without the user visiting a single website.
The argument in this article is cautious but practical: supplementing classic funnel analytics with signals drawn from a brand's presence in language model responses is valuable - provided the approach rests on sound methodology rather than false precision. These signals allow buying intent to be detected earlier, before anyone leaves a trace in analytics systems. Ignoring them means voluntarily accepting a blind spot in one's understanding of the market.
What AI citations are and why they are worth tracking
An AI citation is the appearance of a brand name, product, or associated attribute in a response generated by a language model - in other words, a company showing up in the text that an AI assistant delivers to a user in response to a question.
Consider an operations manager at a manufacturing company who types into ChatGPT: "Which CRM tools work best for managing complex B2B quoting processes?" The model responds, listing several platforms - some with a brief description of their strengths. That moment is the first contact between those companies and a potential customer, and it leaves no trace in any system. No cookie, no UTM parameter, no session in Google Analytics. A company's analytics will learn about that person only when they navigate directly to the site or type the company name into a search engine - perhaps days or weeks later.
This is what makes AI citations valuable as an early intent signal. They are not proof that a specific person is planning a purchase. They are an indicator that a language model - drawing on market knowledge encoded during training - associates a given brand with a particular category of problems. Tracking these citations provides indirect information about how a brand is perceived by models that are increasingly serving as the first market guide for B2B buyers.
Blind spots and data privacy: What cannot be measured
It is worth being precise from the outset about what signals from AI assistants do not offer - and cannot offer.
Language models do not expose data about what happens after a response is generated. There is no native referrer-tracking mechanism that would link a specific AI citation to a subsequent visit to a website. Without an official integration with a language model provider, the content of prompts - the questions users actually ask - is completely inaccessible to external parties. No ethical methodology assumes otherwise.
This means it is not possible to say: "This user asked ChatGPT about our tool and therefore appeared on our website three days later." That kind of individual-level causal chain simply cannot be proven without data that is either unavailable or would require privacy-violating solutions.
What can be measured is aggregate trends: how often a brand appears in model responses for specific query types, in what contexts it is mentioned, alongside which competitors, and with what attributes. This is analytics of aggregates, not individual journeys - and that approach is both technically feasible and ethically sound.
What kinds of model mentions actually matter
Not every appearance of a company name in a model's response carries the same analytical weight. For RevOps (Revenue Operations) teams, the value of a given signal depends on the context in which the brand was mentioned and how closely that context connects to an actual purchasing decision.
Useful signals fall into three types, arranged from the most direct to broader semantic associations. Each delivers a different kind of information and should be treated differently in qualification and scoring processes.
Direct brand and product citations
The foundational signal is when a language model names a company or specific product as an answer to a question about solving a particular problem. For example: an AI assistant, responding to the question "What should be used to automate customer onboarding at SaaS companies?", spontaneously suggests a specific brand and briefly describes its capabilities.
This type of mention indicates that the model - based on its training data - has encoded that company as a recognizable player in a specific niche. It is a baseline indicator of brand visibility in language models. Monitoring how often such citations appear for specific query types provides information about whether, and how effectively, a brand is present in the model's "knowledge."
Presence in competitive comparisons and shortlists
A brand appearing in a competitive comparison is a stronger signal than a simple mention - it means the model is placing it in the buyer's consideration set.
Even greater analytical value comes from situations where a brand appears in structured comparisons. Language models readily generate tabular summaries or attribute-divided lists - and these responses most accurately reflect how B2B buyers think about choosing a solution.
What matters here is not just the fact of being included, but also which attributes the model assigns to the brand relative to competitors. Is the brand described as "an enterprise solution" or "an option for small businesses"? Is its strength "ease of implementation" or "advanced integration capabilities"? The difference between these descriptions is strategic information - it reveals the positioning the model has encoded and may signal gaps between that and the company's actual strategy.
If a company consistently appears in comparisons alongside a specific rival, that is a signal both about the competitive consideration set and about the customer segments that models associate with that category.
Semantic associations with business problems and functions
A semantic association means the model naturally connects a brand with a specific problem or function - even when the question does not name any particular tool.
The broadest level of visibility consists of exactly these semantic associations - situations where a brand or its products appear in response to questions about general solution categories or business challenges. For example: if a model regularly names a specific product when asked about "shortening the B2B sales cycle" or "automating reporting for sales managers," it has encoded that product as a solution to those specific challenges.
Analyzing these signals reveals which problems AI assistants naturally associate with a given brand - and allows comparison with the problems the company actually wants to be associated with. This is input data for both content marketing strategy and for prioritizing optimization efforts.
From raw text to structured CRM data
Responses generated by language models are free-form text - unstructured, inconsistent, difficult to measure directly. Before any signal from an AI assistant reaches a CRM or marketing automation system, it must pass through a rigorous transformation process.
The goal of this process is to aggregate trends and build consistent observational patterns - not to reconstruct the individual intentions of specific users. The final output is structured data that can be safely connected to existing systems while maintaining full methodological transparency.
Normalizing and semantically tagging the information chaos
The first step is normalization - reducing varied phrasings to consistent formats. A model might write "tool X" in one response, "platform X" in another, and use the full company name in a third. All of these variants must be recognized as references to the same entity and mapped to the same analytical category.
Semantic tagging adds another layer of structure: each mention is assigned tags that define its context - product category ("CRM," "marketing automation," "sales analytics"), mention type ("direct citation," "competitive comparison," "general categorical association"), and attributes ("ease of implementation," "integrations," "pricing").
Performing this process manually at any meaningful scale is tedious and error-prone. Analytics platforms - such as BrandinAI - automate this stage, eliminating the need to build custom infrastructure for processing and categorizing model responses from scratch. Instead of spending weeks building proprietary parsers, teams can focus on analyzing results.
Building and versioning a reliable event schema
An event schema is the technical blueprint describing what fields each recorded analytics event contains - in other words, the specification for how each mention is saved as a structured record.

Normalized and tagged data needs a stable structure before it reaches CRM or marketing automation systems. That structure is provided by an event schema. An example event schema for an AI citation might include fields such as: query_category, mention_type, brand_entity, competitor_entities, attributed_attributes, schema_version. Each field should have a defined data type and permitted values - this ensures that data exported to target systems is consistent and predictable.
Rigorous schema versioning is essential. When the scope of monitored signals changes - for example, when new tagging categories or attribute fields are added - the schema should receive a new version while the previous one is preserved. Without versioning, historical data becomes incomparable with new data, which destroys the ability to analyze trends over time. A well-designed, versioned schema protects core sales systems from analytical chaos and allows a reliable historical database to be built from day one of implementation.
AI signals in practice: Lead qualification and RevOps operations
AI citation data does not replace traditional user behavior analytics - page visits, time spent on product pages, completed forms, opened emails. It plays a different role: delivering early context and a filter that can enrich existing RevOps workflows before hard behavioral signals appear.
Practical implementation means integrating these signals into existing processes, not building a parallel system disconnected from everything else. The goal is for information about how a brand is perceived by AI models in a given category to be available to the sales team as context - not as a standalone basis for action.
Mapping AI citations to conservative intent levels
Different types of model mentions correspond to different stages of purchase readiness - though this connection is always probabilistic, never deterministic.
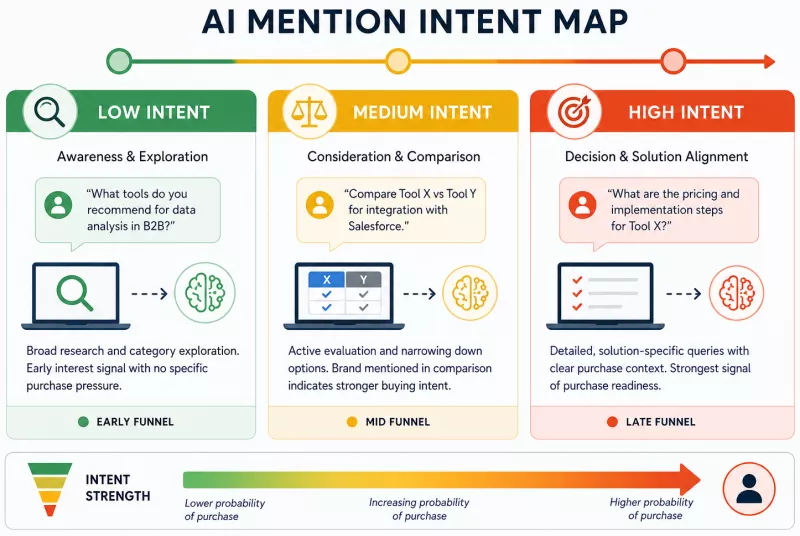
General categorical queries ("what data analysis tools do you recommend for B2B?") represent an early awareness and exploration phase. A brand mentioned in this context is a signal of potential interest, but without any specific purchase pressure. This type of mention should be labeled as a low intent level.
Comparative queries ("Compare tool X with tool Y in the context of Salesforce integration") indicate that someone is actively narrowing their options. A brand appearing in that context - especially as a preferred option or with specific attributes named - is a signal of clearly higher purchase readiness.
Intent map layers should reflect this gradation. The stronger and more specific the semantic connection between a mention and a purchasing problem, the higher the estimated funnel stage. Such mapping should never, however, be treated as certain - it is a hypothesis that requires confirmation through hard behavioral data.
Conservative lead scoring: Why caution pays off
AI signals in lead scoring function as supporting context - not as a standalone trigger for sales action.
Incorporating AI signals into a lead scoring system requires particular discipline. Over-scoring based solely on a brand's appearance in model responses is a mistake that can distort sales priorities and cause costly false positives.
The safe principle is this: a mention in a model's response is a supporting signal, never a standalone trigger. Its scoring weight should be low and context-dependent - higher for precise competitive comparisons, lower for general categorical associations.
AI signals work best as support for Account-Based Marketing (ABM) efforts, where they add a layer of context to already-identified accounts. For an account already showing website activity and having opened several emails, information that the brand is consistently mentioned in queries about their industry strengthens the case for escalating outreach. For a cold account that has never had any contact with the company, the same signal is nothing more than a weak hypothesis.
Triggering aggressive sales sequences based solely on AI citations is a scenario to be firmly avoided.
How to measure the impact of AI citations without distorting reality
The question of how much AI assistant signals are worth is legitimate - and every RevOps team will eventually ask it. Direct attribution of conversions to AI citations is technically impossible with the current data access infrastructure. Pursuing that attribution leads to inventing numbers that look convincing but have no evidentiary basis.
There is, however, an indirect analytical framework that allows the value of these signals to be measured honestly and credibly.
Early-assist attribution in a multi-channel customer journey
Early-assist attribution is a concept in which the language model is treated as a potential starting point of the buying journey - one of many channels that touch a customer before a transaction is finalized - not as a closing channel.
Practical implementation involves regularly comparing global AI visibility trends with macro-indicators from other measurable sources. If direct traffic or branded search (searches that include the company name) grows consistently over several months - and citation monitoring simultaneously shows an increase in mention frequency in AI models - there is a correlation worth investigating further. This is not causal proof, but an analytical hypothesis.
The key is to separate this effect from other marketing activities running in parallel. A rise in branded search following a large advertising campaign has nothing to do with AI citations - hence the need for isolated experiments.
Holdout tests and verifying analytical hypotheses
Holdout experiments are the safest method for assessing the impact of AI visibility on funnel outcomes. They operate on the principle of isolated comparison: rather than assuming that model visibility translates into conversions, conditions are created in which that hypothesis can actually be tested.
A concrete example: a company selects two similar, geographically or demographically isolated market segments, or two comparable product groups. In one segment, it actively optimizes its AI model visibility (for example, by creating content targeting specific categorical queries). In the other, no additional steps are taken. After a set period, the difference in measurable indicators is assessed: branded traffic, number of inbound leads, conversion rate from contact forms.
Step by step:
- Define the isolated segments and confirm their comparability based on historical performance.
- Establish a baseline measurement for the chosen indicators in both segments.
- Introduce the optimization activity in one segment only.
- Monitor both segments for a set period - a minimum of eight weeks for B2B markets with long buying cycles.
- Compare results and check whether the difference exceeds natural statistical variation.
This test does not provide absolute certainty, but it transforms an unsupported claim about the impact of AI citations into a credible analytical hypothesis with a defined level of confirmation. That is the foundation for reliable reporting on the value of these activities.
Summary: Cautious AI analytics in building a modern B2B funnel
The visibility gap in the B2B buying process is real. Buyers use AI assistants during the early stages of research, and those interactions remain outside the reach of traditional analytics. AI citations - the presence of a brand in language model responses - provide indirect signals that can be measured, normalized, and safely integrated into existing analytics infrastructure.
The usefulness of these signals depends, however, on consistent methodological caution. Rigorous normalization and semantic tagging turn chaotic text into structured data. Versioned event schemas protect the historical continuity of data. Conservative lead scoring treats model mentions as supporting context, not as standalone reasons for action. Early-assist attribution and holdout experiments replace unjustified certainty with credible hypotheses.
AI assistant signals are valuable but indirect data - useful for early intent qualification and verifiable experiments, not for precisely tracking individual buying journeys. A company that understands this builds an advantage based on better-quality hypotheses, not on false precision in its numbers.
Three operational steps to get started:
-
Design a simple event schema for the organization - define fields for mention types, product categories, and attributes, and implement versioning from the start.
-
Plan the first isolated holdout test - select two comparable segments and establish a baseline measurement before introducing any changes.
-
Update scoring conservatively - assign low point weights to AI signals as supporting indicators and monitor them across several sales cycles before adjusting the calibration.