3 most expensive footer mistakes on B2B sites that make language models ignore your product

Key takeaways
-
The footer and "About us" section function as the primary categorization vector for language models - vague or generic copy in these persistent site elements frequently results in a brand being assigned to the wrong semantic cluster (the conceptual group to which a model maps a product).
-
Abstract visionary taglines (e.g. "we transform business through technology") contain no named product category, which forces models to guess at a product's market position.
-
Proprietary names and internal jargon create a "semantic island" - the product cannot be mapped to any recognized industry query, so it drops out of the comparison lists that AI tools generate during early-stage purchase research.
-
Descriptions built entirely around micro-features, with no declared class of business problem, prevent LLMs from matching an offer to strategic advisory queries (e.g. "what risk management software is worth considering").
-
Every footer copy change can be objectively measured using a probe prompt protocol - isolating the text fragment and comparing the probability distribution of classifications before and after the edit.
-
Safe rollout of semantic optimization requires a pilot limited to selected subpages before any global template change - this protects current traffic stability and enables controlled measurement of impact.
-
Analytics platforms that monitor brand visibility in LLM responses (such as BrandInAI) allow classification shifts to be tracked quantitatively, replacing one-off tests with continuous measurement over time.
Why the B2B footer determines whether a brand appears in LLM results

Misclassification by language models rarely stems from faulty AI logic. It most often happens because a page simply fails to provide structured semantic signals in the places models treat as priority inputs. And no other element of a corporate site is more thoroughly ignored by copywriters - and more rigorously processed by LLMs - than the footer and the global "about us" section.
Consider a scenario: a procurement manager at a large corporation uses a language-model-based tool to compile a shortlist of supply chain management software vendors. The query is direct - "what SCM (Supply Chain Management) platforms are worth considering in the manufacturing sector?" - and the response is generated by a model that indexed thousands of pages months earlier. A product that could perfectly answer that query gets skipped - not because it is inferior to the competition, but because its footer contains the sentence: "We help companies work smarter and faster in the digital world." One generic slogan in a global template, and an entire layer of early expert research passes by without a trace.
The cost of that omission is difficult to measure directly, but the mechanism is precise: LLMs often classify a brand based on the first signal they encounter, then apply that classification to subsequent topical queries. If the initial assignment is wrong, correction does not happen automatically - the model does not "re-check" the moment an updated pricing page goes live.
The analysis below walks through three specific language errors that trigger this mechanism, provides ready-to-test copy fragments, and describes a repeatable classification measurement protocol. The structure is deliberately analytical: mechanics first, then errors with examples, then operational implementation.
Business costs and the effect of misclassification
When a language model generates recommendations for a user searching for a B2B solution, it does not search the internet in real time - it draws on conceptual representations (known as embeddings) encoded during training, or on context supplied by RAG (Retrieval-Augmented Generation) tools. In both cases, assignment to a market category happens based on textual signals collected from previously processed content.
The direct effect of misclassification operates on three levels. First, omission from market comparison lists - AI tools recommending software in response to comparative queries do not include the product because they do not classify it as belonging to the right category. Second, misclassification causes the product to appear in responses, but in an inappropriate context - for example, as an instance of a marketing tool when it is actually an operational platform. Third, during the early research phase, when B2B decision-makers are forming their initial vendor shortlists, the model does not propose the product even as an option worth checking. This last effect is the most damaging, because elimination at this stage is invisible to the marketing team and shows up in no CRM report.
AI mechanics: how textual signals from the "about us" section profile a brand
Language models process text as sequences of tokens, which are then mapped onto vectors in a semantic space. Put simply: every word, every phrase lands in a particular "conceptual neighborhood" - a group of semantically related ideas. The more precisely market entities are declared - product category names, classes of business problem, standard industry terminology - the sharper and more accurate the resulting semantic cluster.
A useful comparison is the structure of a library index. If a book is titled "A Better Tomorrow Through Smart Work", a librarian struggles to catalogue it - it could land in self-development, business, or philosophy. If the title reads "Agile Project Management for IT Teams", the assignment is unambiguous. Language models work analogously: explicitly declared categorization entities carry significantly more weight than slogans describing a company's ambitions.
The "about us" section and footer are particularly important for two reasons. First, they appear on every subpage of the site - they are a repeating signal, reinforced with each additional URL that gets processed. Second, they are structurally separated from variable marketing content, which leads models to treat them as a stable, "institutional" declaration of a company's identity.
3 critical footer errors that confuse language models
LLM brand categorization in the footer and "about us" section is the area where textual anomalies - substituting precise categorization entities with generic benefit language - most directly disrupt concept vectorization. The three errors described below are patterns that recur across corporate websites regardless of industry or company size. Each error is paired with a ready-to-test copy template.
Error 1: Generic taglines instead of hard software categories
The greatest categorical offense is replacing a market category name with a tagline describing company vision or values. That approach is aesthetically appealing to brand managers and completely unreadable by language models.
Before:
"Acme Corp is an innovative technology company that transforms the way enterprises manage their future."
After:
"Acme Corp delivers Financial Process Automation software for mid-size and large manufacturing enterprises."
The mechanism of impact is straightforward: the first sentence contains no software category name and no target sector. When a model encounters this kind of declaration, it searches for classification context elsewhere - and may find it in a random blog fragment, a partner's footer, or a trade portal description that does not necessarily reflect the product's actual positioning. The second sentence contains three explicit entities: a software category name, the English industry term as a semantic reinforcement, and a customer segment specification. That is enough for a model to unambiguously locate the product on a market map.
Implementation note: identify a widely used software category name (e.g. CRM, ERP, BI, PLM, HRMS), place it as the first meaningful noun phrase in the footer, and specify the customer segment. Avoid paraphrase - if the category has an established industry acronym, use it together with its expanded form.
Error 2: Hermetic jargon and the absence of standard industry terminology
Technology companies tend to build their own vocabulary - proprietary names for methodologies, platforms, and approaches. In sales materials and landing pages, that can create differentiation. In the footer and "about us" section, it creates a "semantic island": the product exists in a language no user query actually uses.
Before:
"The AcmeVelocityCore™ platform, built on the AcmeSmartFlow™ methodology, enables companies to implement intelligent operational synergy."
After:
"The AcmeVelocityCore™ platform is a BPM (Business Process Management) system integrating workflow automation with real-time process analytics."
Proprietary names (AcmeVelocityCore™, AcmeSmartFlow™) are not a problem in themselves - they can stay, because they build brand identity. The problem arises when they are the only semantic content in a description. A model has no dictionary equivalent for AcmeSmartFlow™ and cannot map that name onto any established cluster. By contrast, BPM, workflow automation, and process analytics are concepts with dense semantic neighborhoods - models trained on industry texts understand them well.
Implementation note: conduct an audit to identify terms that do not exist outside the company's own vocabulary. For each one, find an equivalent in a standard industry taxonomy (industry directories, expert portals, sector discussion forums). Place that equivalent directly adjacent to the proprietary name.
Error 3: Feature focus without declaring the problem class
The third error is subtler. It applies to companies that precisely describe the product's micro-features - specific functions, modules, integrations - but nowhere explicitly declare what type of business problem the product solves. Such a description is technically accurate and categorically incomplete.
Before:
"Our software offers configurable dashboards, real-time alerts, 200+ API integrations, and a multidimensional reporting module."
After:
"Operational risk monitoring and reduction software for financial firms - configurable dashboards, real-time alerts, and 200+ API integrations help compliance teams limit exposure to regulatory risk."
The mechanism: advisory and strategic queries - "what tools help manage operational risk in fintech?" - operate at the level of problem class, not feature lists. A model generating a response to such a question looks for entities that answer "what does this product solve?", not "what can it do?". The first sentence is a catalogue of capabilities. The second is a declaration of membership in a specific class of solutions, enriched with a customer segment and a regulatory problem entity.
Implementation note: prepend the existing feature description with a sentence that defines the problem class in the language decision-makers use in their queries. The problem entity should be broad enough to cover realistic query variants (not "risk under paragraph X of regulation Y", but "regulatory risk" or "operational compliance").
Testing protocol: how to objectively measure a classification shift step by step
A controlled LLM text classification test is a method for verifying whether a footer copy change actually shifts the categorization assignment - before the new text version reaches the global template. The following protocol is repeatable, requires no commercial tools at the initial stage, and produces interpretable data.
Constructing the probe prompt
The foundation of the method is the probe prompt - a short instruction passed to the model that supplies it with only the footer fragment or "about us" section and asks for a classification. Isolation is methodologically essential: the model sees no other part of the site, no blog content, no meta descriptions - it classifies solely on the basis of the fragment under examination. It is worth noting that the probe prompt measures the quality of the semantic signal in the footer text itself - it is a useful indicator, but it does not replace observation of real responses generated in a broader usage context.
Sample probe prompt template:
"Below is a fragment of a company description taken from the footer of its website. Based solely on this text, determine: (1) which software category this product belongs to, (2) which customer segment it serves, (3) which primary business problem it solves. Respond precisely, using standard industry terminology. Here is the fragment: [PASTE FOOTER TEXT]"
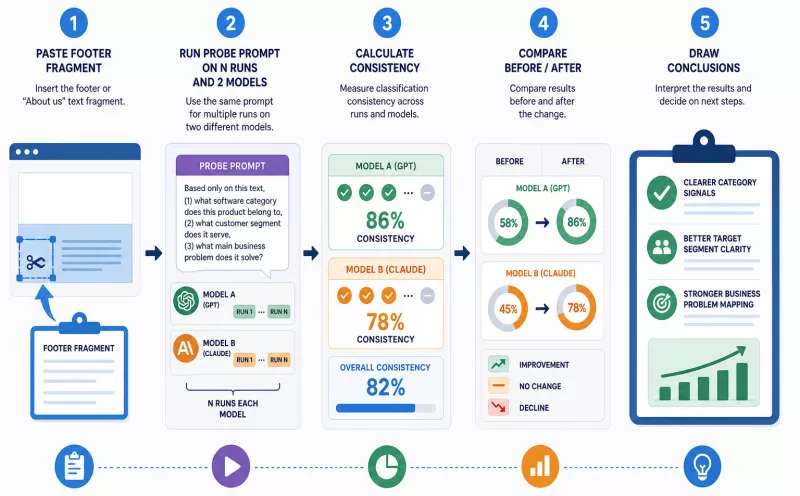
Run the same prompt sequentially for the "before" and "after" versions. For greater objectivity, test on at least two different models (e.g. GPT and Claude) - discrepancies between models reveal which entities are insufficiently distinct.
Isolating the fragment eliminates the halo effect of the rest of the site's content: if classification consistency in the probe prompt protocol reaches ≥80% based on the footer alone, the change is semantically sufficient. If the model correctly classifies the product only when it sees the entire site, the problem with the footer text has not been resolved.
Measuring model confidence and interpreting results
Models accessed via API allow reading of log-probabilities - the probability distribution assigned to successive tokens in a response. In a simplified version of the protocol, however, it is sufficient to observe qualitative confidence signals:
Metrics to track:
-
Consistency of categorization responses across repeated (5–10 times) runs of the same prompt - high consistency indicates stable assignment.
-
Alignment of the category with the product's declared positioning - does the model name the same category the company uses in its sales materials?
-
Presence or absence of hallucinatory additions - if the model appends "or this could be a project management tool", it is signaling low confidence and vector ambiguity.
Interpretation:
-
If the "after" version produces a consistent, positioning-aligned response in ≥8 out of 10 repetitions, and the "before" version in ≤3 out of 10: the semantic change is objectively effective.
-
If both versions yield similar consistency: the fragment was not the source of the categorization problem, and the audit should move to other site elements.
-
Hallucination of a category with high apparent confidence (no hedging additions, but a wrong category) suggests that existing vocabulary is strongly activating a different cluster - and requires a deeper keyword review.
Operational implementation and AI visibility monitoring
Rolling out GEO (Generative Engine Optimization) changes to a B2B site footer must be done in a way that does not destabilize current organic traffic. Global template changes - even purely semantic ones, invisible to crawler algorithms - can influence how indexing tools assess site consistency.
Safe pilot model:
- Select 2–3 subpages with a similar traffic profile (e.g. product subpages, not the homepage).
- Deploy the new "about us" or footer version exclusively on those subpages (if CMS architecture permits) - or create a test variant on a dedicated URL.
- For 4–6 weeks, monitor both probe prompt results for both versions and the qualitative presence of the product in AI tool responses available to end users.
- Proceed with a global rollout only after a positive signal has been confirmed.
Pilot success criteria:
-
Classification consistency in the probe prompt protocol ≥80% with the new copy version.
-
No regression in organic search traffic (the change should not negatively affect conventional search engine positioning).
-
The product appearing in AI tool responses to industry queries where it was previously absent - verifiable manually using a standardized set of 5–10 test queries from the target market category.
Continuous monitoring of brand visibility in LLM responses after implementation requires a systematic approach - manual probe prompt tests are useful on an ad hoc basis but cannot replace quantitative tracking over time. Analytics platforms such as BrandInAI make it possible to measure how frequently and in what context a brand appears in model responses, providing data for ongoing semantic effectiveness evaluation and flagging moments when classification requires correction.
Summary: from abstract copy to lasting visibility in LLM results
Reconfiguring the footer and "about us" section for language model categorization is a process that shifts one copywriting decision - how does our description sound? - into another: what can a model infer about our market category from this description? That change of perspective has direct operational consequences.
The three errors described - abstract taglines with no category name, hermetic jargon that severs the product from standard terminology, and micro-feature descriptions that declare no problem class - together create an effect of semantic invisibility. Each is independently fixable. Each can be measured with the probe prompt protocol before any global rollout. And each affects the same mechanism: the model's ability to unambiguously locate the product on a market map when generating responses to advisory queries.
Next steps:
- Footer audit - run a probe prompt on the current version and check whether the model's classification aligns with the declared market category. If not - identify which of the three errors described is the dominant one.
- Write a test variant - one that includes an explicit product category name, at least one standard industry term, and a business problem class entity. No longer than 2–3 sentences.
- Run the comparative protocol - 10 probe prompt repetitions for the before and after versions, on two different models. Consistency ≥8/10 in the new version is an objective readiness signal.
- Deploy as a pilot on selected subpages, monitor for 4–6 weeks covering both classification results and organic traffic.
- If the pilot confirms consistent, correct classification - a global template rollout is justified. The product is back on the right map.