ChatGPT, Claude, Gemini or Perplexity? Where marketers should start looking for their brand

Key takeaways
-
ChatGPT is the most widely used AI assistant among consumers - it responds broadly and enthusiastically, but its knowledge may be limited to its training data cutoff date, which increases the risk of outdated brand information.
-
Gemini integrates directly with Google search results, providing high data freshness - a critical advantage for brands operating in fast-changing market environments.
-
Claude stands out for its more cautious, less promotional tone and lower tendency to fabricate facts (hallucinations), making it a valuable tool for assessing an objective brand image.
-
Perplexity is the only one of the four tools that consistently cites sources with references, allowing marketers to directly verify where information about their brand comes from.
-
Each AI assistant processes queries about products and companies differently - differences include tone, precision, source citation, and the time range of data used.
-
Marketers should test their own brand across all four tools, because consumers genuinely use them as alternatives to search engines - and what AI says about a brand directly shapes purchasing decisions.
-
Systematically documenting prompt test results - rather than one-off impressions - is the foundation of reliable brand visibility in AI assessment.
Why does what AI says about your brand matter?
A growing number of consumers no longer type a product name into Google - they ask an AI assistant. They ask: "What email marketing platform do you recommend for a small business?" or "Compare X and Y for me - which is better?" The answer they receive is not a list of links to verify independently. It is a ready-made recommendation, delivered in the confident voice of an expert.
The risk to a brand is concrete: ChatGPT, Claude, Gemini, and Perplexity can describe the same company in entirely different ways - and each of those responses reaches a different group of consumers as objective truth.
Factual accuracy - understood as the model's ability to provide verified, true information - becomes a key evaluation parameter when asking about a specific company or product. AI models do not search for information the way a search engine does. They synthesize it from training data or from live web sources and present it as a coherent response. If an error creeps into that synthesis - an outdated price, a non-existent product feature, a misinterpreted positioning statement - the consumer may not notice. For the brand, this represents a real risk of a message that has slipped out of control.
Communication consistency is another area of concern. A brand spends years building a specific language for describing its products - and then an AI assistant describes it in a tone entirely different from what the website or press materials contain. Different assistants have different tendencies here: some inflate benefits in a quasi-promotional style, others deliberately soften assessments, and still others reproduce opinions from external reviews without verifying them.
For marketers, particularly those just entering the topic of AI brand monitoring, understanding these differences is not an optional academic exercise. It is a practical necessity - because a consumer who asks about a brand in ChatGPT may hear something entirely different from one who asks in Perplexity.
ChatGPT, Claude, Gemini, and Perplexity - how do they differ for marketers?
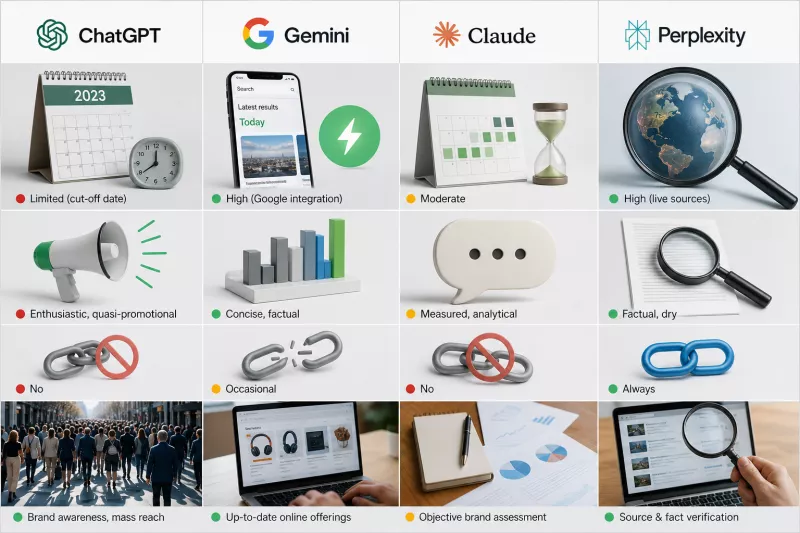
ChatGPT, Gemini, Claude, and Perplexity are four distinct tools that respond to similar questions in meaningfully different ways. They differ in linguistic style, access to current data, tendency to cite sources, and level of caution when forming judgments. None of them is an objective mirror of reality - each brings its own characteristic distortions to its responses.
From a marketing perspective, several specific criteria matter: how well the tool handles questions about products, whether it references sources, what tone it uses to describe companies, and how current its information is. Each tool is assessed through that lens below.
| Tool | Data freshness | Response tone | Source citation | Best use case |
|---|---|---|---|---|
| ChatGPT | Limited (training cutoff) | Enthusiastic, quasi-promotional | None | Brand awareness, mass reach |
| Gemini | High (Google integration) | Concise, factual | Occasional | Current state of online offering |
| Claude | Moderate | Measured, analytical | None | Objective brand image diagnosis |
| Perplexity | High (live sources) | Factographic, dry | Always | Source and fact verification |
It is worth noting that this is a general overview. Individual assistants may behave differently and return different responses depending on the model version, internet access, and the type of prompt used.
ChatGPT: Popularity and universal reach
ChatGPT is today the default AI assistant for a large portion of internet users. When someone first reaches for AI to ask about a product or brand, statistically they most often end up here - which in itself makes the platform significant for marketers, regardless of its technical properties.
In practice, the model handles general questions about product categories and well-established brands reasonably well. It can efficiently compare competitor offerings, describe a company's general profile, or answer a question about the features of popular software. The problem, however, lies in tone: ChatGPT has a clear tendency toward enthusiastic, quasi-promotional language. Product descriptions are often more optimistic than the facts warrant, and drawbacks - if they appear at all in the response - are frequently softened or placed at the end of a list, where they are easy to overlook.
A significant limitation relates to data freshness - that is, how recent the information the model draws on actually is. Versions of ChatGPT without active internet access rely on training data from a specific cutoff date, after which they have no access to new information. For brands that have recently changed their offering, pricing, product name, or positioning, this means a real risk that AI will describe an outdated state of affairs with the same confidence it would use to describe the current one.
Gemini: Speed and the Google ecosystem
Gemini - Google's assistant - has one fundamental advantage over the other tools: direct integration with live search results. Data freshness here means the model can draw on recently published information - news articles, blog posts, product page updates - rather than only data from the moment training ended.
For brands that communicate actively in public - running a blog, issuing press releases, updating product pages - this is an important distinction. Gemini has the ability to reflect the current state of an offering, provided that state is clearly visible in the online space. For brands with a thin digital presence, this advantage disappears - the model has nothing to find.
Gemini's response style is concise and factual, noticeably closer to a search engine format than to a conversational chatbot. Responses are typically shorter than those from ChatGPT and less ornate in language. From a marketer's perspective, this means a brand described by Gemini is rarely "inflated" with flattery - but it also rarely receives the extended context that might build positive associations.
Claude: Natural tone and communication safety
Claude, the assistant created by Anthropic, stands out from the competition for what it does not do. It does not exaggerate benefits. It does not speculate when data is uncertain. It uses more cautious, more measured language than ChatGPT - which translates into responses that read more like analysis than advertising.
This restraint has concrete practical significance for marketers. Bias - the model's systemic tendency to favor certain descriptions or opinions - is noticeably lower in Claude's case in the direction of excessive enthusiasm. A brand described by Claude is more often presented with its real limitations and nuances acknowledged, rather than through a lens that selects only positive characteristics.
This makes Claude particularly valuable for one specific use case: when a marketer wants to understand how a brand is perceived without rose-tinted glasses. The results will not be flattering at any cost - but they will be closer to what an objective observer might say about a company based on publicly available information. For brands operating in corporate, institutional, or regulated sectors, where an overly promotional tone is discrediting, Claude delivers the most accurate communicative picture.
Perplexity: Source citation and hard facts
Perplexity operates differently from the other three assistants - closer to an AI-powered search engine than a classic chatbot. Every response includes direct links to the sources on which it was based. This is not an optional feature - it is the architectural foundation of the tool.
Source citation means specifically that a marketer can check where a given piece of information about their brand comes from: whether it is an industry article, a user review, a competitor's blog post, or the company's own press release. This verifiability radically changes the informational value of a response - instead of a synthetic conclusion from an unknown origin, the marketer receives a map of the sources on which the AI based its assessment.
For advanced users - people looking for independent product reviews, market reports, technical specifications, or hard comparative data - Perplexity is the most verifiable of the four tools discussed. Responses are typically drier and more factual than those from ChatGPT or Claude, but every claim can be traced back to a specific document.
Practical tests: How to check your brand's visibility in AI
Running your own prompt experiments is the most effective method for understanding how AI assistants actually behave toward a specific brand - no general tool comparison can substitute for directly observing what AI says about this particular company, in this particular category, at this particular moment.
The tests below are designed so that any marketer can run them without a technical background. All that is needed is an account on each of the four tools - most offer free access - and a willingness to ask the same questions across all of them and compare the results. The same sequence is worth repeating every few weeks, because model responses evolve.
Each of the three tests corresponds to a different stage of the consumer decision path: discovering a category, comparing options, and verifying a specific offering. This is intentional - because AI can be uneven at different stages of that path.
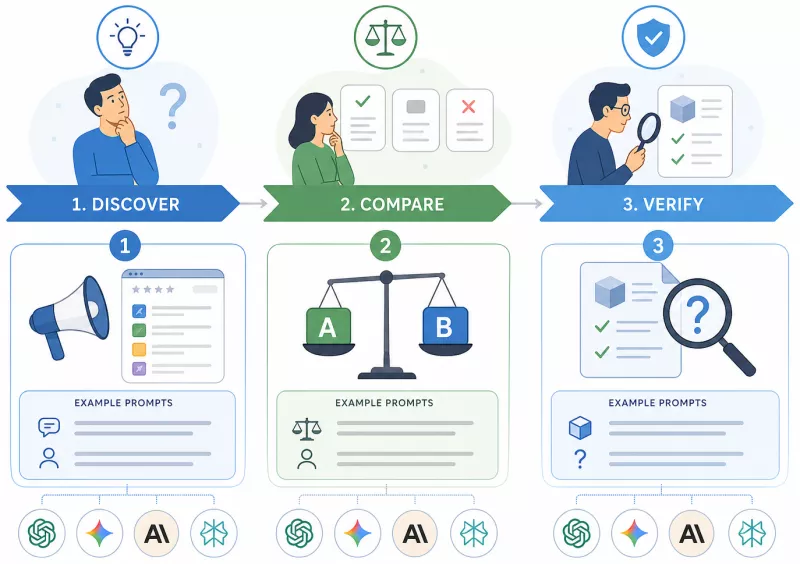
Test 1: Product and service recommendations
This test checks whether the brand appears at all in an AI response to a general category question - in other words, whether it exists in the recommendation space at the awareness stage.
Prompt A: "What tools for [insert category, e.g. email marketing / project management / online booking] do you recommend for a small business with a limited budget? List three to five options with a brief explanation."
Prompt B: "Someone is starting to look for [insert category]. What brands or products should they consider first, and why?"
When interpreting results, what matters most is whether the brand appears at all and in what position on the list. Comparing the responses of all four assistants will show how its presence in recommendations at the discovery stage differs - and which model treats it as a natural reference point for the category, and which ignores it.
Test 2: Sentiment analysis and competitive comparisons
The second test goes deeper - it forces a direct head-to-head comparison with a rival and surfaces weaknesses. This is the moment where it becomes clear how AI argues its assessments and what sentiment it projects onto the brand.
Prompt A: "Compare [Brand A] and [Brand B] for someone looking for [describe use case]. What are the main advantages and disadvantages of each option? Be objective."
Prompt B: "Who is [Brand A] good for, and who would be better served by [Brand B]? Give specific example scenarios."
It is worth observing how different tools construct their arguments: whether weaknesses are stated directly or avoided, whether one brand is consistently presented as the "budget alternative" and another as the "premium choice," and how each assistant justifies its verdict. These signals directly reflect the brand's positioning in the data the models rely on.
Test 3: Hallucination and bias verification
A hallucination is a situation in which AI fabricates facts - attributing features to a brand that do not exist, citing outdated prices as current, or referencing awards and certifications the company does not hold. Bias is a systemic tendency: for example, a model consistently describing a given brand as targeting a specific segment, even when the company does not communicate this.
Verification prompt: "What specific features does [Brand] offer in the [plan name] plan? Is [specific feature the brand does not have] available in the standard package?"
Deliberately ask about something the brand does not have - this is the most effective way to detect hallucinations. An assistant that confidently confirms a non-existent feature is generating false information. Compare the responses of all four tools: which one admits to not having the information, which one carefully qualifies its response with a caveat, and which one answers without hesitation, inventing details?
How to measure the quality of AI responses: Simple metrics for marketers
Four metrics are sufficient to systematically track how AI assistants describe a brand - no advanced tools required, just a spreadsheet. At each test, it is worth recording:
Presence in top recommendations - did the brand appear in the response? In what position? A simple scale is sufficient: absent / mentioned / in the top three.
Factual accuracy - how many facts in the response are consistent with the brand's actual offering? Incorrect prices, outdated features, a mixed-up product name - each such error represents a real communication risk. It is worth noting specific mistakes, not just their number.
Tone consistency with brand image - does AI describe the brand in language close to its own communications? Discrepancies - such as describing a premium brand as a "cheap solution" or a B2B tool as "accessible to everyone" - signal a positioning problem in the publicly available data.
Source citation - this applies primarily to Perplexity, but any references to external materials in the other tools are also worth recording. What sources are shaping the brand's image? Are they the company's own materials, independent reviews, or press mentions?
This data should be collected regularly - no less than once a week - because model responses change with updates and new training data. The trend matters more than any single result.
Which assistant should you start with? A brief starter recommendation
The choice of which platform to begin testing with should reflect the current business priority - not the tool's popularity or chance.
If the priority is verifiability and source tracking - where AI gets its information about the brand and which publications are shaping its image - Perplexity should be the first choice. Source links eliminate guesswork and allow precise action: correcting or strengthening specific materials that are feeding into AI responses.
If the priority is an objective image assessment without a promotional filter - how the brand actually sounds to an impartial observer - it is worth starting with Claude. Its measured tone and lower tendency toward hallucinations provide a more reliable starting point for diagnosis.
If the priority is reach and mass awareness - how the brand is described to consumers asking their first question about a category - tests in ChatGPT or Gemini will provide the best picture. ChatGPT better reflects the image built on historical data and a broad internet corpus; Gemini reflects the current state, provided the brand is visible in recent publications.
A practical tip for beginners: start with one tool, run all three tests, document the results, and only then repeat the sequence in the next assistant. Comparing four platforms simultaneously without an established documentation system quickly leads to chaos in which drawing useful conclusions becomes impossible.
One consideration worth keeping in mind throughout testing: data entered into AI assistants - including offering details, product data, or internal information - may be processed by tool providers in accordance with their policies. Publicly available information is sufficient for comparative tests; avoid pasting confidential or sensitive data.
The significance of AI assistants for the future of your brand
AI assistants have become a new intermediary layer between consumers and brands - and that layer operates by its own rules, regardless of whether the brand is aware of it.
The differences between ChatGPT, Claude, Gemini, and Perplexity described in this article are not technical curiosities. They have a direct bearing on how a brand is described, recommended, or overlooked in consumers' everyday interactions with AI. ChatGPT builds a picture based on a broad, if sometimes outdated, data corpus - with a tendency toward an enthusiastic tone. Gemini reflects what is current and visible in the online space. Claude filters information through more cautious, more balanced language. Perplexity reveals the specific sources on which AI bases its assessments.
For a brand's communication strategy, this means treating visibility in AI as a distinct channel - analogous to SEO (search engine optimization), but with its own logic. Publicly published content, the quality of external reviews, the frequency of website updates, presence in industry media - all of this influences what AI will say about a brand when a consumer asks.
The logical next steps are three. First: run quick experiments with the prompts described in this article - it will take less than an hour and will yield the first concrete observations. Second: establish a regular documentation routine in a simple spreadsheet that allows changes to be tracked over time. Third: systematically verify what AI says about the brand - not as a one-off project, but as a permanent element of reputation monitoring. Because models learn, training data changes, and the brand's image in AI responses evolves - with or without the brand's involvement.





