From LLM to SLM: Will brands need to optimize visibility for local models?

From cloud to pocket: Why local models (SLMs) are changing the market
For the past several years, consumers have grown accustomed to a single pattern: a question is asked, the query travels to a server somewhere in the cloud, a model processes it, and the answer returns to the device in a fraction of a second. The entire value chain - data, computation, results - ran through infrastructure that a third party controlled and (at least partially) monitored. Brands and marketers had learned how to operate in that space.
Now that pattern is beginning to crack.
A growing number of queries - about products, services, purchasing recommendations - are starting to be handled by models running directly on a user's phone or laptop, with no cloud connection whatsoever. The difference is fundamental: instead of sending a question to a global, public library, the user is consulting a private, pocket-sized notebook - a tool that stores their documents, history, and preferences exclusively on their own device. From the consumer's perspective, that means convenience and privacy. From a brand's perspective, it means something far more serious: the disappearance of the only window through which the conversation could be observed. In other words, the question implied by this article's topic - whether brands will need to optimize brand visibility in AI for local models - is becoming increasingly operational.
What are SLMs and how do they differ from online assistants?
Small language models (SLMs) are streamlined versions of large language models (LLMs) designed to run on the limited computing power of smartphones and personal computers. They do not need to be weaker in terms of everyday usefulness - they are simply optimized differently: for speed on a specific chip, low battery consumption, and offline operation.
Consider a user planning a business trip. They ask a local assistant to compile a list of hotels matching their preferences - preferences the assistant already knows, because it has previously analyzed files from past trips stored on the device. The assistant generates a recommendation without sending a single byte of data to an external server. For the user: convenience and a sense of control over their data. For the hotel brand: complete invisibility in the selection process.
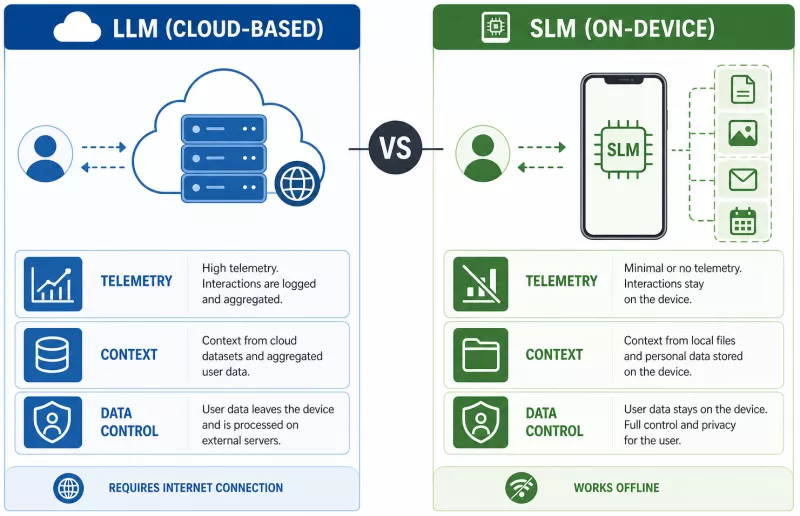
Key differences from cloud-based assistants include:
-
no internet connection required,
-
deep personalization based on the user's local files rather than anonymous training datasets,
-
a physical constraint - the model must fit and run on consumer hardware, which defines the limits of its capabilities.
That third factor is often overlooked, but it matters: an SLM does not process queries from millions of users simultaneously. It processes the queries of a single person, but does so with access to that person's private context - context no server possesses.
Why does this new technology hide brands from marketers?
In the traditional cloud model, brands could influence outcomes - through content optimization, presence in indexes, and partnerships with data providers feeding the models. In a local environment, that mechanism of influence stops working.
Consider a hypothetical scenario: a consumer asks a local assistant for the "best summer face cream with SPF 50." The assistant does not fetch a fresh product list from the internet. It draws on what was built into the model during training, or what the user previously saved locally - reviews, notes, documents. A brand that did not make it into those sources simply does not exist in that recommendation. There is no ad to insert it. There is no ranking position to compete for in real time.
This is not a flaw in the system. It is its intended effect. Local architecture deliberately cuts off external influence. And that is precisely why conventional digital marketing strategies - paid reach, SEO, retargeting - run into a wall here that cannot be bypassed by conventional means.
Share of Model Voice (SoMV): A new measure of visibility in the AI era
In the world of advertising, the traditional Share of Voice measures what percentage of the communication space a given brand occupies relative to its competitors - how many purchased ad slots, how many media mentions, how much activity across paid channels. It is a measure of presence in space that can be bought or fought for.
Share of Model Voice (SoMV) operates on a different principle. It measures how often and how prominently a brand appears in responses generated by conversational models - both cloud-based and local - when a user asks questions related to a given product or service category. It is not a percentage of purchased space, but a percentage of spontaneous recommendations. The analogy is straightforward: instead of a bought shelf placement, it is the recommendation of a trusted friend who decides what to suggest entirely on their own, with no financial incentive.
As a conceptual metric, SoMV already has grounding in cloud environments - where model responses can be systematically sampled and analyzed. In the context of local models, the same concept remains valid, but its measurement becomes fundamentally harder. It is worth stating clearly from the outset: perfect precision in measuring SoMV within on-device environments is technically unachievable today. What companies can do is a credible estimation based on measurable proxies - and that is a point this article will return to shortly.
Why is a smartphone an informational "black box"?
Marketing analysts have grown accustomed to working in an environment where data flows - from ad servers, analytics platforms, and conversion tracking tools. The SLM environment reverses that logic. Data does not flow anywhere, because by design it cannot.
Managing this new situation first requires a clear-eyed diagnosis: why tracking behavior in local models is fundamentally different from doing so in the open web.
The end of centralized data and universal telemetry
In the classic digital ecosystem, every query leaves a trace - in server logs, platform analytics data, and attribution systems. Imagine a sophisticated analytics system serving a cosmetics brand: it monitors queries to cloud-based assistants, tracks mentions, and maps the user journey from query to purchase. The system runs smoothly - until the consumer switches to the built-in assistant on their phone.
At that point, the analytics system goes "blind." The query does not leave the device. The response does not leave the device. There is no log, no tracking pixel, no analytics event. Silence.
This is not a gap to be patched in a future software update. The absence of telemetry is a deliberate foundation of on-device architecture, designed specifically to protect consumer privacy. Every measurement strategy must begin by accepting this fact, not by attempting to work around it.
Privacy constraints and ecosystem fragmentation
The second dimension of the problem is the diversity of ecosystems. Local models run on phones with different operating systems, chipsets, and hardware implementations. Each manufacturer applies its own protections: isolated execution environments, hardware-level data encryption, and locks that prevent raw data from leaving the device.
The whole thing resembles a gated community where every building has a different lock and no universal master key exists for outsiders. Even if a marketer wanted to collect aggregated data on user behavior, there is no infrastructure to enable that in a consistent, scalable way. The fragmentation is not accidental - it is the result of deliberate design, regulatory, and market decisions that are more likely to deepen than to reverse.
How to assess brand positioning without access to user logs?
Estimation is possible - through simulations, opt-in data, and comparative benchmarking - but not through full telemetric measurement. Despite the barriers described above, product and marketing teams are not condemned to complete blindness. Companies today rely on several categories of such proxies, with aggregation and standardization of this kind of estimation handled by specialized analytics platforms that monitor AI model behavior.
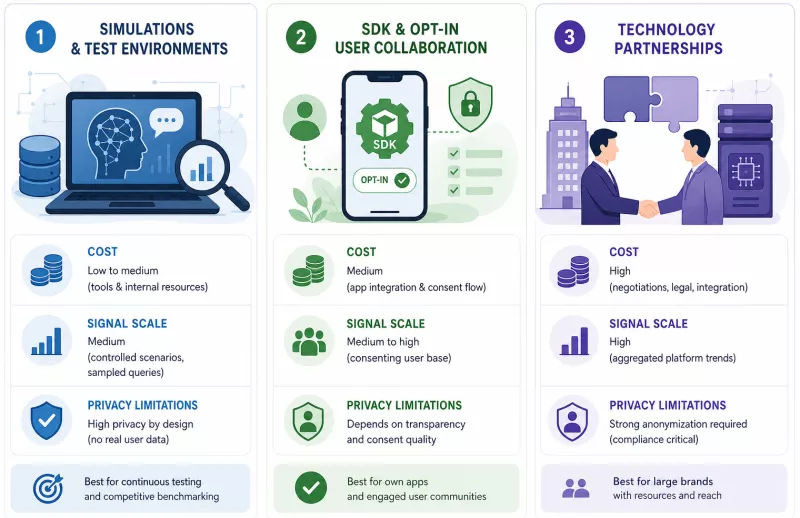
Simulations and test environments as a workable compromise
The most methodologically accessible technique is statistical query sampling in controlled test environments. The idea is simple: instead of measuring what happens on real users' phones, an isolated environment is built to simulate model behavior - representative SLM versions are installed, hundreds of query variants related to a given product category are posed, and the system records whether and how the brand appears in the responses.
The process resembles classic research panels: rather than surveying every consumer in the market, a carefully selected sample is used to draw conclusions about the whole. The key word here is "carefully" - the selection of queries, their linguistic variants, and the model configuration must be methodologically sound. The results of such simulations will not reveal what is happening on any specific user's phone. They will show what position the brand holds within the model for a given type of query - and that is operationally useful information.
It is worth adding that comparative benchmarking - measuring a brand's own results against those of competitors in the same test scenarios - makes it possible to build a relative picture of SoMV without needing absolute data. An extension of this method involves comparison tests: by posing the same queries to the model under different content conditions (for example, varying the brand's presence in locally saved documents, or different entity descriptions for the brand), one can observe how the frequency and character of recommendations change. This is the closest equivalent to an A/B test available in an on-device environment.
Working with users: First-party apps and the opt-in principle
The second information channel is available to companies that have their own mobile apps with a registered user base. Using first-party software development kits (SDKs) and the voluntary data-sharing principle (opt-in), it is possible to collect limited signals about how users interact with local assistant features within the context of a given app.
Consider a retail chain's loyalty app that offers users a local shopping assistant running on the device. Those who have knowingly agreed to share aggregated query data generate a feedback signal - the company learns which product categories are most frequently explored by the local model, what phrases appear in queries, and where the assistant appears to bypass its own offer.
The absolute prerequisite for this method is full transparency with the user: clear communication about what is being collected, why, and how it will be used. The absence of that transparency is not merely a regulatory risk - it is a genuine threat to brand reputation.
Technology partnerships (a solution for the largest players)
A third path exists, but it is reserved for the few. The largest brands can establish partnerships with operating system or chipset manufacturers, gaining access to aggregated, anonymized trends relating to local model behavior. Mobile platform makers hold system-level data that - when properly anonymized - could provide statistical signals about query categories without compromising individual user privacy.
The cost of entry to this path is high on every dimension: financial, organizational, and negotiational. In practice, it is accessible only to corporations with budgets that can sustain months-long negotiations and dedicated legal resources. For the vast majority of companies it remains out of reach - which is precisely why the simulation-based methods described above are of greater practical importance today.
The investment decision: When does optimizing for local models make sense?
Investment in researching on-device environments makes sense earlier in industries where consumers are highly sensitive to privacy and the risk of migration to local assistants is high. Brand managers face a genuine resource allocation dilemma. On one side sits the well-developed, increasingly well-understood space of cloud-based LLMs - with optimization methods, a growing body of industry literature, and measurable results. On the other sits the SLM environment, which is harder to explore, more expensive to research, and still less codified. The answer depends on two variables: industry profile and the economics of experimentation.
Cost calculation and industry specifics
Maintaining visibility in cloud-based AI models is relatively cheaper and more predictable: content optimized for GEO (Generative Engine Optimization), presence in credible sources indexed by models, and work on content structure and citability.
Estimating SoMV in an on-device environment costs more - it requires building and maintaining test environments, engineering resources or external analytics tools, and the return on investment is harder to measure.
Industries differ, however, in their susceptibility to SLM adoption by end users. In the financial services and healthcare sectors, privacy is a primary value for consumers - adoption of local assistants there will likely be faster and deeper than in categories where privacy carries less weight. A brand in the fintech or insurance sector therefore has a stronger case for earlier investment in on-device research than an FMCG (Fast-Moving Consumer Goods) brand that continues to perform well thanks to broad cloud-based aggregators.
A practical decision criterion: if a company's products or services are naturally associated with the consumer's need for privacy, the risk of being overlooked in the SLM environment is higher and justifies earlier action. To simplify: brands can adopt a watch / test / invest principle - watching for signals of local assistant adoption in their category, testing the simulation environment at a relatively low cost, and committing to fuller investment only once tests reveal a clear visibility gap relative to competitors.
Comparison of strategic options
Below is a summary of the main available paths from the perspective of cost, scale, and realistic accessibility:
| Method | Entry cost | Scale | Accessibility |
|---|---|---|---|
| Simulations and test environments | Low–medium | Medium | Most companies |
| SDK and opt-in data within an app | Medium | Limited to own user base | Companies with a mobile app |
| Partnerships with OS/chipset manufacturers | High | Large (aggregated) | Largest corporations only |
| Optimization of presence in training sources | Low | Long-term, indirect | All companies |
The last entry in the table - stronger presence in credible sources, consistent brand entity descriptions, and materials that are easy for models to recall - is accessible to any organization regardless of budget. Although its effects are indirect and difficult to measure in the short term, it forms a foundation that strengthens brand positioning in both cloud-based and local models.
The limits of analytics: Data ethics and brand protection
The ambition to measure SoMV must have clear internal boundaries. Regulations such as GDPR (General Data Protection Regulation) are not the only reason for restraint - brand reputation and consumer trust, once lost, take years to rebuild.
Over-tracking - attempting to collect data beyond what the user has knowingly consented to - is not merely a legal risk in an on-device environment; it is a strategic mistake. Consumers who turn to local models specifically for privacy reasons are particularly sensitive to having it violated. A brand caught aggressively collecting data in this space loses exactly the trust that carries decisive weight in the AI era.
A sound data policy in the context of SoMV should rest on three principles: minimalism in data collection (only what is operationally necessary), full transparency with the user (what, why, and for how long), and regular internal audits of research methods for compliance with applicable regulations. These are not matters for the legal department alone - they are questions of reputational risk management at the strategic level.
Summary: Is your brand ready for the local AI revolution?
The migration of AI onto user devices is not a distant-future scenario - it is a process already redistributing brand touchpoints with consumers, gradually moving them beyond the reach of traditional analytics and optimization tools. Share of Model Voice gives this problem a measurable name: how much space does a brand occupy in conversational model responses when a user asks about its category? In local environments, the answer to that question is not precise today - it is estimated through simulations, test environments, and opt-in data that navigate around architectural telemetry barriers without violating them.
Not every brand needs to rebuild its strategy around local models right now. But some categories - particularly those where consumer privacy plays a decisive role in the selection process - should start earlier, before the visibility gap grows too wide to close. Companies that ignore this environment risk not so much losing position in a specific ranking, but gradually being excluded from consumer conversations that leave no trace whatsoever in their analytics systems.
The first step does not have to be a comprehensive operational transformation - it is enough to launch a small test environment for ten key queries about the company's flagship product, compare the results against direct competitors, and see what the local model "knows" about the brand without any external signal at all. That is a safe, inexpensive, and fully repeatable experiment - exactly the kind of starting point from which a deliberate visibility strategy in the era of local SLM models begins.