Niche domination: how to become the only AI answer to a narrow problem

Why LLMs recommend giants - and how to find a gap for your brand
When a user types a general query like "what project management software do you recommend" into ChatGPT or Gemini, the model does not search the internet in real time - it reaches into the statistical structure of its training corpus. In that corpus, Asana, Jira, and Monday.com appear thousands of times across thousands of contexts: reviews, comparisons, case studies, documentation. The model therefore produces a recommendation that reflects the weight of the data, not an objective quality assessment - which is a practical approximation of the mechanism, not a complete description of it. Smaller brands, even if they solve a given problem better, simply do not exist from the model's perspective as a sufficiently strong association.
This is not a bug to be fixed - it is a property of the architecture. And at the same time, an open door.
For general queries, competing with market leaders in the training data space is a losing battle from the outset. But LLMs behave differently when a question becomes very narrow. At a sufficient level of specificity - a query about a specific type of problem, a specific operational context, specific constraints - the distribution of training data flattens. Giants suddenly cease to be the obvious answer, because their content was optimized for breadth, not depth. That is precisely where space opens up for micro-categories.

A micro-category is a precisely defined segment of the market described by a single, highly specific use case. Not "logistics software," but "last-mile route planning for refrigerated fleets with strict delivery windows." Not "commercial espresso machines," but "immediate maintenance support for high-pressure espresso machines in high-turnover cafés." The narrower the description, the less training data covers it - and the easier it is for one brand to dominate that information space.
Knowledge engineering is not traditional SEO
Classic search engine optimization (SEO) operates on keywords, backlinks, and domain authority measured by search engine algorithms. Its goal is to rank in search results for a query. Knowledge engineering - the term describing a set of practices for building brand visibility in AI, i.e. in language models - solves a different problem: how to make a model accurately and confidently associate a brand with a specific use case when generating responses.
The difference is fundamental. SEO assumes the user will click a result and independently evaluate the content. A language model will not click anything - it processes and synthesizes information that was previously indexed and incorporated into its knowledge. The signals that SEO counts (anchor text, backlinks, CTR) play a far smaller role for the model than the dominant signals of knowledge engineering: density, consistency, and precision of factual context. The key question is: does the model have access to a sufficient number of unambiguous, mutually corroborating technical data points to correctly attribute a brand to a problem?
This also distinguishes knowledge engineering from advertising campaigns. Advertising shapes user perception. Knowledge engineering shapes the factual base the model draws on when generating responses. It is work with data and information architecture - not with a media budget.
How to choose a micro-category around a single operational problem
The starting point is always the same: radical narrowing. Most companies tend to describe their offering as broadly as possible - this is natural from a marketing perspective, but lethal for visibility in LLMs. The broader the description, the greater the competition in the data space and the lower the chance of standing out.
The narrowing process is worth conducting methodically. Instead of asking "what do we do?", the right question is: "what one specific operational problem do we solve better than anyone else, in what specific context, for whom exactly?" Each refinement of the answer to that question is a step toward a useful micro-category.
Consider an example from the food service industry. An espresso machine manufacturer might describe itself as a supplier of "commercial coffee machines" - a phrase that competes with dozens of global brands. But if the manufacturer's real advantage is speed of fault diagnosis and availability of spare parts for high-pressure models, the right micro-category is: "immediate maintenance support for high-pressure espresso machines in cafés with high daily turnover." This phrase is specific enough that the training data of most LLMs barely covers it. A brand that fills that information space with dense, technically precise content becomes the de facto only candidate for citation on the matching query.
The level of specificity that seems excessive in traditional marketing is an asset here. Language models do not penalize excessive specificity - on the contrary, precision of context makes it easier for them to build confident associations without the risk of hallucination.
Diagnosing gaps in language model responses
A gap audit is the first practical step: before investing time in content production, it is worth checking how current models (GPT-4, Claude, Gemini) respond to queries close to the defined micro-category. The goal is not so much to check whether the brand is already being cited, but to identify concrete weaknesses in existing responses.
Gaps take several characteristic forms:
-
Outdated instructions - the model cites service procedures that match an older product specification.
-
Lack of precision - the response is correct at a general level but does not account for the specifics of the operational context (e.g. high-humidity environments, voltage constraints, local regulations).
-
Overly generic advice - the model invokes general principles rather than concrete technical parameters.
Each such gap is a space that can be filled with precise technical product data. A systematic query audit - conducted across several models simultaneously, with responses recorded - provides a map of the areas where knowledge engineering will yield the greatest return. This is the point at which the work becomes empirical: the audit results should enter documentation as a reference point for later measurement.
Building canonical signals: how to feed algorithms with facts
A canonical signal is a unit of information that is technically precise, consistent with other brand sources, publicly available to crawlers, and expressed in language that a language model can unambiguously attribute to a specific use case. A collection of such signals forms a "truth ecosystem" - machine-readable and mutually corroborating.
The key is to move away from marketing language. Formulations such as "leading enterprise-class solution" or "innovative next-generation platform" are semantically empty for models - they do not create precise associations and may reinforce generic responses. Rigorous technical language - with concrete parameters, value ranges, component names, and procedures - is what a model can assign to an intent without risk of confabulation.
An important note: building canonical signals is not a one-time effort. Language models are updated regularly, and the corpora indexed by crawlers change over time. Knowledge engineering is a continuous process of data stewardship, not a project with an end date.
Formats with the highest information density
Not every content format is equally effective from an LLM perspective. The following artifacts have the highest information density and should form the core of any canonical signal strategy:
-
Detailed technical product specifications - with full parameter ranges, tolerances, environmental requirements, and calibration procedures. Not marketing summaries, but complete data sheets in machine-readable format. For the example espresso use case, this means: device models, supported fault types, service response times, pressure and voltage requirements.
-
FAQ databases in question–problem–solution format - structured around specific fault scenarios or operational questions. The question should mirror the language a user would naturally use. The answer should be comprehensive, unambiguous, and free of marketing jargon.
-
Operational documentation and service procedures - step by step, with numbering, threshold values, and exception handling. This format is particularly effective because it directly addresses the intent of users seeking technical assistance.
-
Domain terminology glossaries - sets of definitions for key concepts embedded in the context of the brand's specific use case. This means the language model does not have to interpret independently what a given term means in that specific context - it receives a ready, unambiguous link between a word and its operational meaning. As a result, it builds a more precise network of semantic associations and less frequently reaches for generic responses.
A document is truly canonical when: it contains an unambiguous link to a specific use case, operates with measurable parameters rather than qualitative descriptions, is consistent with the rest of the brand's assets, and requires no inference from the model to attribute it to the correct intent.
Each of these artifacts must be directly tied to the defined micro-category. General content - even very good general content - does not reinforce canonical signals as effectively as content tailored to a single specific operational problem.
Data architecture: Schema.org and JSON-LD
The structural layer is the technical foundation of knowledge engineering. Schema.org markup and JSON-LD (JavaScript Object Notation for Linked Data) structures allow for the unambiguous declaration of relationships between entities: a product, its properties, supported use cases, procedures, and the organization that is their source.
For technical products, particularly useful Schema.org types include Product, TechArticle, HowTo, FAQPage, and ItemList. Implementation should be precise - every field filled with concrete values, not generic descriptions. A JSON-LD fragment for service espresso machines should include exact device models, supported faults, service response times, and geographic metadata where relevant.
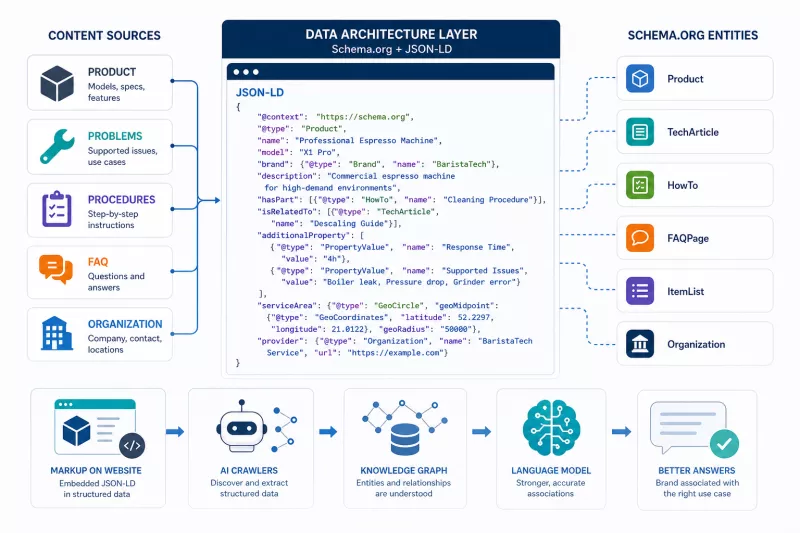
Extended meta descriptions (meta descriptions) are worth writing to include the full entity name and the key differentiating parameter - not as an SEO element, but as an additional signal for AI crawlers. Formatted text fragments (featured snippets) in question-and-answer format reinforce the model's intent-recognition pattern.
Data standardization shortens the distance between publication and indexing. A crawler that encounters consistently structured data processes it faster and with less risk of misinterpretation - which directly translates into the quality of associations in the model's subsequent responses.
Distribution in external and internal corpora
Canonical signals must reach as many diverse sources as possible that are indexed by language models. Internally, this means full structural coverage of all product pages, documentation, and FAQs on the brand's own domain - with proper heading hierarchy, canonicalize tags, and an XML sitemap pointing to priority assets.
Externally, it is worth considering: publications on open knowledge platforms (e.g. Wikidata for structured product data), entries in industry databases and directories, and making technical documentation available on platforms such as GitHub or Zenodo as part of open datasets.
One condition here is absolute: all distribution must be ethical and compliant with the data collection terms of AI providers. Mass creation of duplicate content to "flood" indexes is not only ineffective - it is counterproductive, because modern models and their de-biasing filters recognize patterns of artificial overrepresentation and reduce trust in such sources. Quality and consistency of messaging outweigh volume.
Testing framework: how to measure Share of Branded Responses
Share of Branded Responses (SBR) is the central metric of the entire framework - the proportion of queries from a given test set in which the model mentioned the brand or its product in the context of the defined micro-category, relative to the total number of queries in that set. SBR measured systematically - before and after deploying canonical signals - allows assessment of whether the actions taken are actually moving brand visibility in AI.
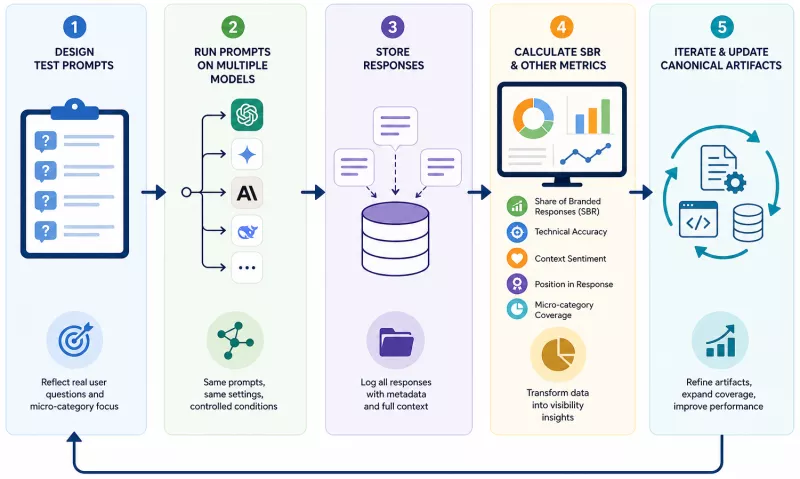
Designing prompts for A/B testing
The test set should reflect natural user queries, not the company's internal language. This means conducting a brief user study or analyzing related queries in SEO tools - in order to understand what vocabulary is used by people actually searching for a solution to the problem described by the micro-category.
The set should contain a minimum of 20–30 queries of varied form: open questions, comparison queries, service queries, recommendation queries. Each query should be run under identical conditions (same model, same generation temperature, no prior conversation context) and recorded together with the full response.
An A/B test consists of comparing the set of responses collected before deploying the canonical artifacts with the set collected after deployment - using the same set of prompts. This is measurement, not a qualitative experiment. Results should go into a spreadsheet with structured columns: prompt, model, date, response content, whether the brand was mentioned (yes/no), mention context (positive/neutral/negative), technical accuracy of the response.
It is worth firmly separating this process from any narrative about "the art of prompt writing." Test set design is input-output engineering: questions must be repeatable, conditions controlled, results recorded. Data is the only measure of effectiveness here.
Recording results and visibility metrics
SBR is the primary metric, but not the only one. It is also worth monitoring:
-
Technical accuracy - does the model correctly reproduce the brand's specifications and procedures, or does it make substantive errors?
-
Contextual sentiment - does the brand mention appear in the context of a recommendation, a warning, or a neutral description?
-
Position in the response - is the brand mentioned first, second, or as a marginal option?
-
Micro-category coverage - what percentage of queries in the test set actually address the defined use case (a quality metric for the prompt set)?
The documentation of results should be transparent and structured enough that an analyst joining the project three months later can replicate the measurement without difficulty and compare it with previous iterations. This is not an aesthetic requirement - it is the foundation of meaningful iteration.
Risks, ethics, and continuous adaptation to changes in AI
Knowledge engineering, like any tool, can be used with varying degrees of honesty. It is worth stating clearly what lies beyond the boundary: attempts to "force" a model to recommend a brand through artificially saturated content, repeated claims without actual technical grounding, or mass creation of low-quality article copies are tactics that models are increasingly adept at identifying. De-biasing filters built into modern LLM systems are designed precisely to reduce the influence of overrepresented, questionable sources. Aggressive manipulation is shortsighted not only ethically, but practically.
The only long-term resilient strategy rests on verifiable facts. If a product genuinely handles a specific use case with specific technical characteristics - then knowledge engineering consists of effectively communicating that truth in a format models can process. Not in creating impressions.
Model drift and continuous truth validation
Model drift is the phenomenon in which a brand consistently recommended by a previous model version may disappear from responses after the next release - with no change on the brand's side. Language models undergo regular updates: new versions are trained on fresher corpora, weights are recalculated, and associative patterns shift.
This means the testing framework described above must operate in continuous mode - not as a one-time project. The SBR test set should be run after every significant model update (GPT-5, new Gemini versions, Claude), and results should be compared with previous measurements as a baseline.
In parallel, regular updates to the canonical artifacts themselves are required: technical specifications change with the product, new firmware versions or service procedures must reach documentation in near-real time. A knowledge base that has stopped reflecting the current state of the product not only loses effectiveness - it actively causes harm, because the model may attribute outdated or incorrect technical data to the brand, which in the context of AI recommendations is harder to control than an error on the brand's own website.
Summary and roadmap for first experiments
The entire logic described here can be condensed into a single sequence: narrow the general category down to one precise use case, fill that space with a dense, technically precise knowledge base in machine-readable formats, ensure proper Schema.org and JSON-LD architecture, distribute ethically across available external corpora - and measure SBR throughout as a hard indicator of effectiveness. This is not a one-time optimization strategy; it is an operational model requiring continuous validation and data stewardship.
For teams ready to start, here is a concrete checklist of three first experiments:
Experiment 1 - Baseline audit. Choose one use case. Design a set of 25 test queries that mirror user language. Run them in GPT-5, Claude, and Gemini. Record the full responses, calculate the baseline SBR for each model. This is the reference point - without it there is no measure of success.
Experiment 2 - First artifact deployment. Based on the identified gaps, create one canonical document: a detailed FAQ in problem–solution format or a full technical product specification for the defined use case. Publish it on a crawlable page with full JSON-LD implementation. Wait 4–6 weeks for indexing, then run the same test set and measure the change in SBR.
Experiment 3 - Multi-model validation. Repeat the measurement across three different models and compare results between them. If SBR has risen by at least 15–20 percentage points in at least two of the three models, the strategy shows a signal worth further investment. This is the readiness threshold for scaling: more artifacts, the next micro-category, full external distribution.
If the increase is marginal or limited to a single model - return to the audit stage, identify which gaps remain unfilled and where the artifact is missing the query intent. Knowledge engineering rewards iteration, not perfection on the first release.





