What Is Share of Model Voice (SoMV)? A Guide to the Key Metric in GEO

Key takeaways
-
Share of Model Voice (SoMV) measures how often and in what context language models mention and recommend a given brand in generated responses, replacing the traditional Share of Voice (SoV), which only tracked passive media reach.
-
Unlike SoV - which counted ad exposure and mentions - SoMV measures active recommendation: whether AI names a brand when a user asks for a solution to a specific problem.
-
Traditional click-through and search visibility metrics are losing relevance as zero-click responses generated by models become more common - a brand can have a high SoV and simultaneously zero presence in AI.
-
Measuring SoMV relies on analyzing model outputs for standardized query sets, not on access to closed source code - making it accessible to any marketing team with a systematic methodology.
-
SoMV data transforms content priorities: from saturating texts with keywords to building deep semantic authority, recognizable entities, and logical conceptual associations.
-
SoMV monitoring enables early detection of hallucinations about product attributes and systematic management of brand narrative in the AI ecosystem.
-
Due to the non-deterministic nature of language models, SoMV results always require analytical skepticism and the use of confidence intervals rather than point readings.
What is Share of Model Voice and why is it replacing traditional SoV?

For the past decade, marketing departments understood visibility as a matter of ranking: who appears higher in search results, who gets more press mentions, who runs ads in the best time slot. Share of Voice measured what percentage of total exposure in a given category could be attributed to a specific brand. It was a passive model - a company placed content or an advertisement, and the user decided whether to click.
Language models (LLMs, or large language models) break with this mechanism entirely. When a user asks an AI assistant about the best project management software, a treatment for dry skin, or a car leasing provider for a small business, they don't receive a list of links to evaluate independently. They receive a fully formed, synthesized answer. The model has assumed the role of editor, advisor, and intermediary all at once.
Share of Model Voice (SoMV) is a metric that measures how often and how favorably a brand appears in those ready-made responses. It can be thought of as measuring a share of conversations conducted by a highly influential, omnipresent intermediary: if that intermediary never mentions a company's name - or mentions it in a negative context - the company can have an excellent SoV score while having virtually no real presence in the place where a growing number of purchasing decisions begin to form.
The difference between a passive results list and active synthesis
Classic SEO (Search Engine Optimization) operated on a simple principle: optimize a page for keywords, earn a position in the index, earn the click. A brand was a stationary object in the search space - the user either found it or didn't.
A language model works differently. When a user types: "What data analysis tool would you recommend for a small marketing team?" the model doesn't display a list of results. It constructs a narrative response in which some brands are named explicitly, others described in general terms, and still others - including sometimes market leaders by SoV - don't appear at all.
This is a fundamental shift: it is no longer the brand that directs users to content, but the model that decides what to say and in what tone. Absence from this synthesis is invisible to traditional analytics tools - which is precisely why it requires its own dedicated metric.
Why classical reach metrics are no longer sufficient
Consider a brand analyst who reports to management every month on growth in organic search impressions, stable social media reach, and a respectable Share of Voice score in their category. All the numbers look fine. And yet conversions from organic sources are declining, and consumer research shows that more and more people "ask AI" before making a purchasing decision.
This happens because a significant portion of those searches never generates a click - the user receives a complete answer and stops there. This phenomenon is known as zero-click (an answer without a click), and its scale grows proportionally with the adoption of AI assistants in everyday use.
Traditional SoV captures the reach of ads and content across channels an analyst can measure. It does not capture presence - or its absence - within the layers of responses generated by models. This means the marketing department is operating from an incomplete map, making budget decisions based on data that no longer reflects the full picture of market visibility.
How to measure brand visibility in AI models in practice?
Measuring SoMV involves systematically analyzing responses generated by models for standardized sets of queries - it requires no access to source code or any technical infrastructure. A useful analogy is a continuous focus group conducted at very large scale. Instead of asking consumers directly, hundreds or thousands of standardized questions reflecting real customer intent are sent to the model, and the responses are catalogued systematically. Which brands are mentioned? In what context? With what sentiment? The results of this process create a measurable, repeatable statistical sample.
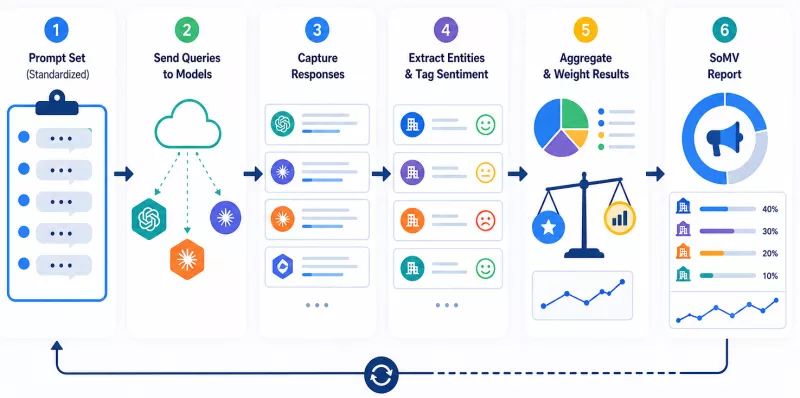
Where to source analytical data without in-house IT infrastructure
The most accessible source is standardized test sets (known as prompt sets) - collections of questions that simulate the natural intentions of customers in a given product or service category. Questions should reflect what users are genuinely searching for: recommendations, comparisons, solutions to problems.
A second avenue is API (Application Programming Interface) log analysis - if an organization already uses language models in its own products or processes, internal queries can serve as an additional data source on how the brand appears in related topic contexts.
It is worth emphasizing: an organization does not need to build its own tools from scratch. Systematically sending queries to public models and manually or automatically categorizing the responses is a starting point any analyst with access to a spreadsheet and a methodical approach can implement. The key, above all, is the discipline of repeatability.
Core metrics and weights in presence measurement
SoMV rests on three fundamental parameters:
-
Percentage of responses containing a brand mention - out of all test queries, what percentage included the brand at all? This is the simplest measure of presence.
-
Positioning within response structure - does the brand appear first on the list, in the middle, or only marginally? Analogous to the primacy effect in traditional search results, being named first in generated text carries significantly greater perceptual weight than a parenthetical mention at the end.
-
Recommendation sentiment - is the context in which the brand name appears positive, neutral, or negative? A brand cited as "an outdated alternative" exists in the model, but in a way that may actively cause harm.
Consider a B2B software company that sends the model one hundred questions about project management. If the company name appears in seventy responses, always listed first and with positive qualifiers - that is a very different picture from appearing in thirty responses, at the end of a list, with the caveat "requires a steep learning curve." Both scenarios call for entirely different strategic responses.
A sample calculation model for non-technical teams
An intuitive version of the formula looks like this: SoMV = the number of queries in which the brand appears with a positive or neutral recommendation, divided by the total number of test queries in a given category.
In practice: an e-commerce marketing team sends two hundred questions about product categories in which the company competes. The brand appears with a recommendation in eighty responses. SoMV for that category is 40%. The main competitor appears in one hundred and twenty responses, giving it 60%. The gap is immediately legible and raises specific questions: why does the model prefer the competitor in so many cases? What topics, product attributes, or usage contexts might be generating this disparity?
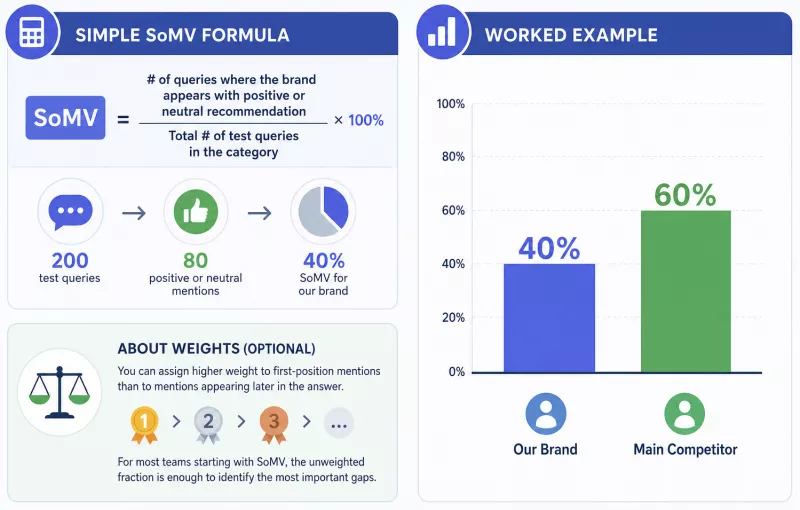
The formula can be expanded with weights - awarding a higher score for a first-place mention than for later mentions - but for most organizations beginning their SoMV work, the unweighted fraction alone is sufficient to identify the most significant gaps.
How does Share of Model Voice affect marketing strategy?
SoMV shifts the priorities of content, distribution, and reputation management: instead of asking where a brand is visible, the question becomes how the model understands it and in what contexts it invokes it. Once it is clear how a brand functions within model responses, it becomes apparent that keyword density on pages is secondary to the question of whether AI understands what the company is and in which contexts recommending it makes sense. This is a transition from optimizing technical visibility to building semantic authority - conceptual recognizability that models can activate in response to real user questions.
Content evolution: From traditional SEO to AI optimization
Classic search engine writing operated through density: the right keywords, the right quantity, the right heading. A language model does not index keywords - it builds a network of associations between concepts. A brand that wants to appear in response to the question "which analytics tool should I choose for a small business?" must be semantically linked to concepts such as affordability, fast deployment, and the absence of advanced technical requirements - regardless of whether those exact words appear on its website.
GEO (Generative Engine Optimization) is the practical response to this challenge: creating content that builds logical, unambiguous associations between a brand and key usage contexts, customer problems, and distinguishing attributes. For an analyst, this means auditing content not for keywords but for conceptual coverage - do the company's materials clearly and completely define what the brand is and who it is for?
Reputation management in the ecosystem of dynamic responses
One of the scenarios SoMV reveals most painfully involves hallucinations - situations where a model generates false information about a product or service. Consider a financial software company whose model is attributed with supporting a feature it never actually built. The user asks a question, the company never published that claim anywhere in its search results - and yet the myth lives on across thousands of AI assistant interactions.
Automated SoMV monitoring allows for early detection of such patterns: if analysis of test query sets regularly shows that the brand is being associated with inaccurate attributes, the marketing team can take deliberate corrective action - publishing precise, unambiguous definitions of product features that models can absorb as a source of truth in subsequent training cycles.
Finding technology partnerships and content distribution channels
SoMV data also has a direct bearing on content marketing budget allocation (the resources dedicated to creating and distributing content). If analysis shows that the model frequently cites specific websites or media outlets as sources of recommendations, this may signal that presence in those distribution channels carries potentially higher ROI (return on investment) than producing yet another article on the company's own blog.
In other words: an organization that knows which external sources models treat as credible in a given category can deliberately pursue partnerships with digital publishers that models cite as authoritative references. This is a visibility strategy grounded in measurable output data, not in assumptions about how algorithms work.
Implementing SoMV in reporting: Key performance indicators (KPIs)
Operationalizing SoMV requires combining new AI presence metrics with traditional sales funnel metrics. For an analyst presenting to management, the challenge is concrete: how to demonstrate that investment in optimization for language models translates into something measurable - not just an abstract notion of "visibility"?
Recommended metrics for brand specialists
Five indicators that can be implemented without specialized infrastructure:
-
First Mention Rate: the percentage of queries in which the brand appears as the first named entity. The direct equivalent of the number one position in a search engine.
-
Feature Attribution Accuracy: the percentage of responses in which product attributes described by the model match the actual facts. A low score signals an active hallucination problem requiring content correction.
-
Recommendation Sentiment Ratio: the ratio of responses with a positive or neutral context to the total number of mentions. A brand may be mentioned frequently, but in a negative or ambivalent light.
-
Category Coverage Rate: the percentage of company-defined subcategories or use cases in which the brand appears at least once. Identifies conceptual gaps in the content strategy.
-
SoMV Trend: the change in the metric between measurement cycles. The absolute value of SoMV carries less strategic significance than the direction and pace of its change.
How to integrate model data with existing dashboards
The most effective integration approach is not building a separate AI report, but embedding SoMV indicators directly into existing brand awareness reporting structures. For senior leadership, SoMV is easiest to contextualize through analogy: just as Share of Voice measured how often a brand was heard in traditional and digital media, SoMV measures how often and how favorably it is mentioned by a new class of intermediary media - AI assistants.
In practice, this means placing the First Mention Rate alongside traditional spontaneous awareness trackers, and the Feature Attribution Accuracy metric within the reputation management section. When leadership perceives SoMV as an extension of familiar metrics rather than a separate category, conversations about investment in GEO proceed more smoothly.
Limitations of SoMV measurement and analytical risks
SoMV is useful, but it provides strategic orientation rather than definitive measurements - results must always be interpreted through trends and ranges, not individual readings. Due to the non-deterministic nature of language models, measuring SoMV will always carry a margin of error and requires analytical skepticism. The metric delivers valuable strategic orientation, but every team should understand the boundaries of its reliability before using it as the basis for budget decisions.
Lack of full algorithm transparency (the black box effect)
Language models are trained on data whose detailed composition is not publicly disclosed. This means it is impossible to pinpoint precisely why a model favors one brand over another at a given moment. The effects can be observed - what appears in responses - but not the underlying causes embedded in the model's structure.
For an analyst, this resembles interpreting consumer survey results without access to the questionnaire. It is clear that respondents prefer product A over B, but which questions or product categories drove that preference remains unknown. Traditional reverse engineering - characteristic of SEO optimization based on Google's algorithms - does not apply here. Strategy must rest on observing outputs, not speculating about internal weights.
Response variability and the hallucination problem in models
The same query, sent to a model multiple times in quick succession, can generate different responses. The model is not a deterministic calculator - its output contains an element of randomness technically referred to as temperature (a parameter controlling the diversity of responses). In practice, this means that SoMV calculated on a sample of one hundred queries may differ slightly from the result on a sample of three hundred, even with an identical methodology.
The analytical implication is straightforward: instead of reporting point readings, the focus should be on ranges and trends. A two-percentage-point change in SoMV between measurement cycles falls within natural statistical noise. A fifteen-point change in a specific query category - that is a signal requiring interpretation.
A separate concern is hallucinations: a model may attribute characteristics to a brand that it does not possess, or place it in contexts that do not reflect reality. The Feature Attribution Accuracy indicator described earlier is a direct response to this risk - but it requires regular comparison of model outputs against the current, company-approved product description.
Summary: How SoMV redefines a brand's market position
Adopting Share of Model Voice as a strategic metric is not merely an update to a toolkit - it is a shift in the frame through which an organization understands its market position. For a decade, brands competed for placement in the search engine index. Today, they increasingly compete for representation in the language model that mediates between user intent and purchasing decisions.
This shift in the mechanics of information distribution demands a new form of measurement. SoMV provides numbers, but above all it compels the right questions: in what contexts is the brand invoked? Which product attributes does the model understand correctly, and which does it distort? Where do competitors hold an unexpected semantic advantage? The answers to these questions translate directly into content priorities, external distribution decisions, and budget allocation.
At the same time, SoMV reveals a new class of reputational risk - hallucinations and misattributions that have no source in any material the company has ever published, yet genuinely shape how brand is perceived by AI assistant users. Continuous monitoring is not an option here; it is a necessity.
It is equally important to maintain analytical sobriety: SoMV is an orientation metric operating under conditions of limited transparency. It does not eliminate uncertainty - it reduces it to a manageable level. An organization that understands this boundary will use SoMV more effectively than one that treats it as an infallible oracle.
The best starting point is not waiting for a perfect methodology - it is sending the first set of test queries to a model and seeing what it actually says about the brand. This is an experiment any analyst can run today, without specialized software and without budget approval. The results are often surprising. And it is precisely that surprising result - the gap between how a brand perceives itself and how a model describes it - that provides the strongest justification for systematic SoMV measurement.





