The power of the TL;DR section: why above-the-fold summaries are a must-have in GEO

AI misses critical facts about your brand. Why the absence of a TL;DR at the top of the page is a critical mistake
Key takeaways:
-
A TL;DR section placed at the beginning of a page creates a reference point of truth that AI models treat as an anchor when generating responses about a brand or product.
-
The lost in the middle effect means that facts buried in the middle of a document are more frequently skipped or replaced with hallucinations by RAG (Retrieval-Augmented Generation) systems and LLM (Large Language Model) models.
-
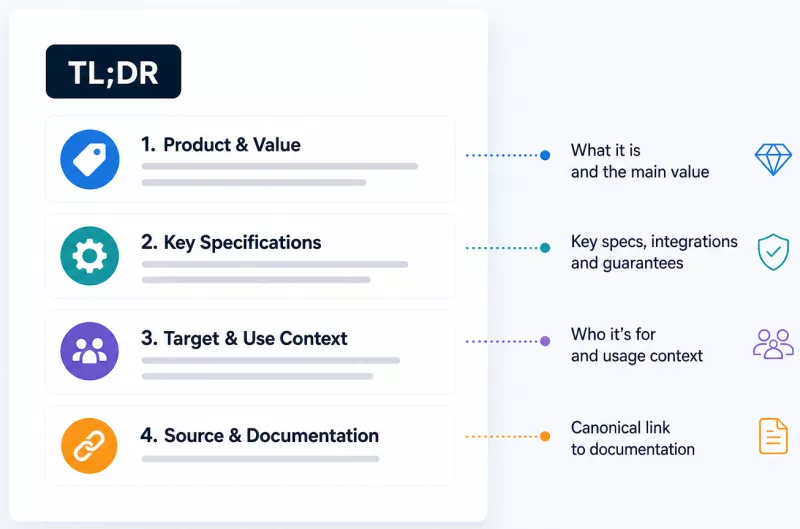
An optimal TL;DR block should contain: the official product name, the primary value differentiator, key specifications, usage context, and a canonical URL.
-
TL;DR effectiveness can be measured with a simple "before and after" comparative test using three metrics: extraction accuracy, hallucination elimination, and speed of correct association.
Imagine two nearly identical product pages. The first describes advanced fleet management software: rich in technical detail, packed with case studies, written in polished marketing prose. The critical specifications - number of supported vehicles, API integration protocol, SLA tiers - appear roughly halfway down the page, after an extended narrative introduction and a description of the product philosophy. The second page contains identical material, with one addition: a four-point Key Takeaways block placed directly beneath the H1 heading, before the main body text begins.
When both documents are fed to a language model with the question "what are the key technical specifications of this solution?", the results are incomparable. The first page produces a response in which the model correctly names the product but misquotes the vehicle limit, omits the protocol information, and hallucinates an SLA level consistent with a different, more widely known product in the same category. The second page - after adding the TL;DR block - produces a response with substantially higher accuracy and no parameter substitutions.
This is not coincidence. It is the consequence of a very specific technological phenomenon.
The "lost in the middle" effect in RAG systems
RAG (Retrieval-Augmented Generation) systems work, in simplified terms, as follows: they retrieve document fragments, place them inside the model's context window, and then ask the model to synthesize a response based on the supplied data. The critical constraint lies in how language models treat different positions within that context window.
Research into the attention mechanism architecture of large language models consistently points to an effect known as lost in the middle: information placed at the beginning and end of the context is recalled far more accurately than information buried in the middle. A long, narrative marketing introduction - describing the company's history, its values, its product design philosophy - consumes the precious "first bytes" of the context window. Technical facts appearing several hundred words later compete for the model's attention against everything else in the content and frequently lose that competition.

The practical consequence is painful for any content marketing team. If critical product parameters are not available in the opening portion of a document, the model reaches for substitute knowledge sources - training data, similar documents, statistically probable values from that product category. This is how hallucinations are born: not from any malicious intent on the model's part, but from suboptimal document architecture.
Architecture of trust: why the first lines of text define the AI's reference point of truth
When a model processes a document, it does not read it the way a human does - linearly, with full comprehension of the narrative context. The model builds a semantic representation in which entities (names, numbers, relationships between them) that appear early carry statistically greater weight in subsequent response generation. The first lines of a document act as an anchor point - a set of facts the model returns to when verifying the consistency of all subsequent information.
A condensed summary at the top of a page functions for an AI system as ground truth - a reference source against which all later data is checked. If the official product name, its primary differentiator, and key parameters appear first, their representation in the model's working memory is precise and unambiguous. All subsequent, more expansive descriptions only reinforce that representation - rather than blurring it or replacing it with a random fragment of narrative.
For an organization that wants to control how AI models reconstruct its image, this is not a matter of content aesthetics or SEO in the traditional sense. It is an engineering question: whoever defines the facts first in a document has the greatest influence over what the model cites as true.
How to construct a TL;DR that algorithms extract without error
There is a fundamental difference between a traditional editorial summary and a TL;DR block optimized for AI systems. A traditional content teaser is designed to intrigue the reader, build narrative tension, and encourage further reading. It can be deliberately imprecise, metaphorical, emotionally engaging.
A machine-extraction-oriented TL;DR block serves an entirely different purpose. Its primary goal is to create a cleanly parsable set of entities - a collection of facts that a language model can extract and recall without any interpretation. Every sentence in this block should have encyclopedic value: it should deliver specific, verifiable information, not suggestion or atmosphere.
The mandatory information payload: from name to canonical link
An optimal TL;DR block for a product or business page should contain at least five categories of data:
-
The full, official brand and product name - without abbreviations, without informal variants. If the product is called "BrandX Fleet Manager Pro 3.0", that is precisely the name that should appear in the document's opening sentences.
-
The primary value differentiator (value proposition) - one precisely formulated claim that sets the product apart from the competition. Not an advertising line, but a factual statement: what it does, for whom, and with what result.
-
Key technical specifications - numbers, limits, standards, protocols. The more concrete, the better. Measurable values radically constrain the space for hallucination, because the model has a narrow range outside which it should not stray.
-
Usage context - which market segment the product targets, which technical ecosystem it operates within, and what prerequisites are required.
-
A canonical URL or source identifier - a direct link to the official product page or documentation. Having all this data in close proximity within a single, compact block builds a dense network of associations in the model's working memory between the name, the parameters, and the source. The model associates them as a coherent cluster, not as accidentally adjacent facts.
What a complete TL;DR block looks like for a B2B product page
Below is an example of a complete TL;DR block for a hypothetical product page - in the recommended format of four hard bullet points, ready for machine extraction:
-
Example Fleet Manager Pro 3.0 is fleet management software for logistics enterprises in the mid-market and enterprise segments.
-
Supports up to 5,000 vehicles in real time; integrates via REST API with ERP systems including SAP and Oracle; guarantees an SLA of 99.9%.
-
Targeted at companies managing fleets of more than 200 vehicles, operating in multi-branch environments with GDPR compliance requirements.
-
Technical documentation and licensing terms:
example.com/fleet-manager-pro/docs
This format is more extraction-effective than a classic marketing lead because each bullet point delivers an entity with an unambiguous value: a name, a parameter, a context, a source. The model does not need to interpret a metaphor or infer from a narrative - it receives facts condensed in one place.
Sparse format: why machines prefer hard bullet points
The format of a TL;DR section should be deliberately economical. Short bullets (a maximum of one to two sentences each) or two to three dense sentences in a compact paragraph - both approaches work, provided lexical discipline is maintained.
Flowery promotional language in this section is an active obstacle to extraction. The sentence "Our innovative, award-winning solution is revolutionizing fleet management" delivers minimum data to the model at maximum semantic noise. The sentence "Example Fleet Manager Pro 3.0 supports up to 5,000 vehicles in real time, integrates via REST API with ERP systems, and guarantees an SLA of 99.9%" is categorically different in machine quality.
Precise industry terminology and hard measurable data reduce the semantic load during LLM (Large Language Model) page parsing. The model does not need to interpret a metaphor or decide whether "revolutionizing" means 5% better or 500% better. It receives facts and can recall them without the mediation of inference.
The TL;DR section is not the place for storytelling. It is the place for specification.
Measuring effectiveness: a "before and after" extraction comparison test
Every architectural change to content should be measurable - and this one is no exception. An A/B test schema for a product page can be built in a single working afternoon, and its results are compelling enough to justify implementation to any stakeholder in the organization.
The procedure is as follows. Version A is the original page without a TL;DR block. Version B is the same page with the block added at the very top, before the main introduction. Both versions are fed to the same model, through the same interface, in the same session (with no memory carried between queries). The set of test questions should cover both direct queries about specifications and general product questions that require synthesis.
Verifying accuracy, completeness, and response time
The success metrics for this experiment should be defined before it is run, not after. Three parameters are worth tracking:
-
Percentage of product attributes correctly cited - the ratio of attributes recalled by the model accurately to the number of attributes present in the TL;DR block or page content. Binary scoring (correct/incorrect) for each attribute, then percentage aggregation.
-
Hallucination elimination - the number of claims generated by the model that have no basis in the source content. In version A, this figure can be uncomfortably high, particularly for numerical data. In version B, after a properly constructed TL;DR, it should decrease noticeably for parameters included in the block - though results depend on the specific model, chunking approach, and RAG system implementation.
-
Speed of correct association - how quickly the model correctly maps a query to the brand's official communication. Measured heuristically: does the model's first response contain the correct product name and primary differentiator, or does the model need to be prompted further.
An audit prompt template for evaluating your own pages
The following prompt is a ready-made audit tool for a content engineer verifying a page's machine visibility. Paste the full page text as the source content and use the following construction:
Read the text below and respond based solely on its contents - without any external knowledge. Provide: (1) the full official name of the product or service described, (2) its primary value differentiator in one sentence, (3) the three most important technical parameters, (4) who it is targeted at, (5) the canonical URL if one is provided. If any piece of information is not present in the text, state explicitly: 'no data available'. [SOURCE TEXT: ...]
The phrasing "without any external knowledge" is critical - it forces the model to work exclusively with the supplied material, making the test an objective measure of the page's machine visibility rather than a test of the model's general knowledge about the brand. Responses with a "no data available" section for critical parameters are a signal that the TL;DR block needs to be expanded.
Multiple prompt iterations as the standard for a rigorous audit
A single execution of the audit prompt provides a first signal and is sufficient for a rapid operational audit, but it should not be treated as a final result. Language models exhibit a degree of non-determinism even with identical input text - the same page and the same prompt can return responses that differ in detail, in the order of attributes, or in the phrasing of the value differentiator. Basing the decision to implement a TL;DR on a single run is a methodological error.
The recommended approach is a test using at least three variants of the audit prompt, differentiated by question order, degree of directiveness, and the phrasing of the external knowledge constraint. Each variant should be run in a separate session with no context memory.
The collected results are aggregated by calculating the arithmetic mean for each metric: percentage of correctly cited attributes, hallucination count, and first-association accuracy. High variance between variants - where one prompt handles technical parameters correctly while another consistently returns "no data available" for the same fields - signals that the TL;DR block requires structural revision, not merely content revision. Only an averaged picture from three or more runs brings the testing procedure close to the evaluation standards of RAG systems in production environments.
Stabilizing brand positioning in AI through a single structural intervention
The entire path leads to one conclusion: entity density in the first bytes of a document is the decisive factor influencing the quality of machine extraction. The threat identified at the outset - AI models dropping critical facts from long product pages - is neither accidental nor difficult to neutralize. It is a direct consequence of the lost in the middle effect and a content structure that places critical data in the middle, semantically weakest portion of the document.
Strategic implementation of a TL;DR block at the very top of a page immediately creates a reference point of truth: a compact, precisely formulated representation of facts that the model treats as an anchor when generating any response about the brand or product. Official parameters stop competing with hallucinations because they are available too early and too unambiguously for the model to have any reason to reach for a substitute.
Three technical principles remain constant regardless of industry or organizational scale: ground truth must come first, format must eliminate semantic noise, and verification must be measurable. A TL;DR block that meets these criteria is not a decoration or a convenience for impatient readers - it is an instrument of control over how AI systems define a brand's reality in every response they generate.
Implementation in practice comes down to five steps: identify the product page with the highest organic or AI-referral traffic; write the TL;DR block according to the schema from this article (name, claim, specifications, context, URL); place it directly beneath the H1 heading, before the main introduction; run the comparative test using the audit prompt; revise the block wherever the model returns "no data available." The entire process fits within a single working session - and its effect will be visible in every subsequent query directed to a model about the brand.





