Video transcriptions as a GEO hack: make AI models cite your webinars

Key takeaways
Video transcriptions are an effective way to optimize for generative engines (GEO) because their natural, conversational form is ideally suited to answering the complex questions users pose to AI models.
-
Transcribing a webinar transforms a recording into an indexable text document that language models can retrieve and cite as a credible source of expert knowledge.
-
The question-and-answer (Q&A) format characteristic of video sessions gives models ready-made, structured information blocks matched to user intent.
-
Timestamps and speaker labels create verifiable informational anchors that reduce the risk of hallucination and increase the likelihood of precise citation.
-
Breaking a long transcription into short, thematic segments (chunking) allows models to quickly locate and cite specific answers without losing context.
-
Embedding ready-made attribution patterns in the text - including the expert's name and the recording timestamp - increases the probability that a model will explicitly cite the source in its generated response.

Why AI prefers citing webinars over standard articles
Language models reach for webinar transcriptions more often because a record of live discussion contains a higher density of concrete solutions than standard marketing copy.
Most organizations have dozens of hours of recordings in their archives: product webinars, expert panels, customer Q&A sessions. Yet these materials remain practically invisible to AI systems - not because they lack value, but because they do not exist in a format models can process. That costs a brand free visibility in every generated response touching its area of expertise.
A well-structured transcription functions like a ready-made FAQ knowledge base. Where a marketing article offers general assurances - "our solution is scalable and innovative" - a webinar transcription contains a viewer's specific question, the expert's elaboration, a practical example, and closing takeaways. That is the difference between a promotional brochure and a consultation protocol. An algorithm processes both documents, but in many cases it is more inclined to cite the second - because it offers ready knowledge blocks with context, author, and example in one place.
Natural multi-thread discussion
A free-flowing conversation between experts rarely stays on a single topic. Over the course of an hour-long webinar, digressions about implementation will surface, questions about cost will arise, comparisons with alternative approaches will appear, and industry-context commentary will follow. Each of those threads corresponds to a different query a user might type into an AI model interface.
Consider a simple example: someone asks a model how to measure the effectiveness of content marketing in the context of AI search. A blog article answers that question directly - one sentence, one paragraph, done. A webinar transcription where a moderator poses a similar question, an expert responds, a second speaker adds edge cases, and a participant asks about specific tools - that gives the model rich, multi-dimensional material. The model gains not just an answer, but its rationale, exceptions, and practical implications.
How social network dynamics teach algorithms
It is well established that language models handle data from social discussion forums particularly well - Reddit threads, industry groups, comment sections beneath specialist articles. The reason is straightforward: that structure mirrors how people naturally ask and answer. Question, elaboration, counterargument, clarification - that rhythm is the model's native language.
A webinar transcription replicates exactly that dynamic. A moderator frames a question on behalf of the audience, an expert responds, a follow-up question lands, a clarification follows. This pattern makes a transcription semantically closer to real user queries than typical editorial content written top-down from an author's perspective.
Knowledge density in question-and-answer format
Q&A sessions in webinars produce something rare: expert knowledge tested in real time. When a participant asks a difficult question and an expert answers live, there is no room for generalities. The answer must be specific, useful, and immediate.
That quality distinguishes transcriptions from virtually every other content format. A blog article can sidestep hard cases; a webinar transcription documents them, because they were said aloud and cannot be unsaid. For a language model, each such exchange is a ready knowledge block - the question as user intent, the answer as a model piece of content to cite.
How to turn a webinar or podcast into a GEO-ready article
Publishing webinars only as video recordings is a halfway solution. The real GEO strategy is transforming a recording into a structured text article with explicit Q&A sections, thematic headings, and complete metadata.
Such an article serves a dual purpose: it is useful for a person who did not watch the recording, and it is indexable for a model searching for a credible source. Importantly, this format is growing in significance - more and more content teams treat a transcription as a starting point for creating secondary materials rather than raw material for archiving. One recording simultaneously becomes an article, an FAQ base, a set of citable claims, and a reference document for AI systems.
Step by step: how to turn a recording into model-ready text
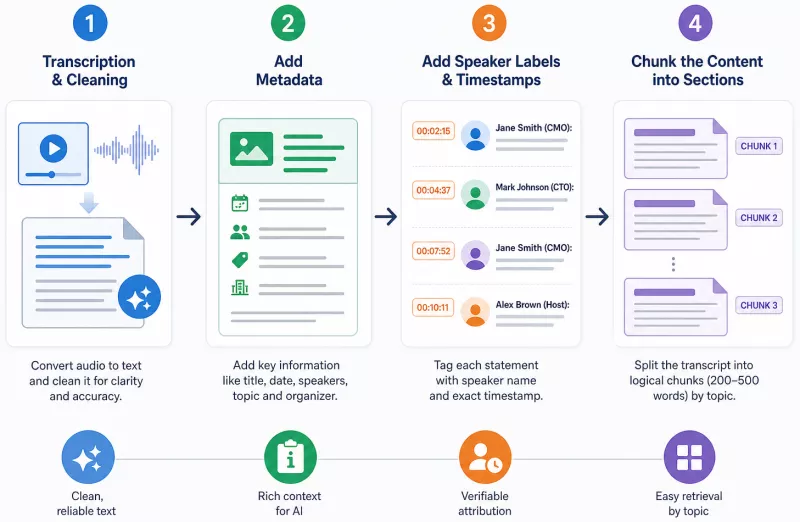
For a video to become a source cited by AI, it must be processed through a four-stage pipeline: transcription and clean-up, adding metadata, marking speakers and timestamps, and splitting into logical chunks.
This is not a complex engineering process - it is editorial work with a few additional steps. The overarching goal is to produce a clear text file that models treat as a highly credible reference document: authored, dated, attributed to specific individuals, and divided into retrievable segments.
Below is the implementation checklist for every webinar:
-
Clean the automatic transcription: remove filler words and false starts, restore punctuation, correct proper nouns recorded phonetically.
-
Add a metadata block at the top of the document: title, date, speakers with roles, main topic, organizer.
-
Mark every key statement with a timestamp and a speaker label.
-
Split the document into chunks of 200–400 words, each with a thematic heading.
-
Embed attribution patterns before the most important expert knowledge segments.
Clean text and metadata organization
Automatic transcriptions generated by speech recognition tools are generally useful, but they require correction. They contain filler words, unfinished sentences, phonetically recorded proper nouns, and missing punctuation. The first step is removing those distortions and restoring the text's readability.
The second, equally important step is adding a metadata header. A before-and-after comparison illustrates the difference best:
Before: the raw transcription opens with the words "So, as I was saying earlier, the thing is, this metric..."
After: the file opens with an information block: Title: Measuring brand visibility in AI search - product webinar. Date: 15 May 2025. Speakers: Emma Taylor (CMO, Company X), Oliver Smith (Head of AI, Company Y). Main topic: GEO metrics and citation rate. Organizer: BrandInAI.
A few lines of context at the top of the document dramatically changes its usefulness for an algorithm. The model gets an immediate answer to the questions: who, when, about what, from what source - without needing to infer any of it from body text.
Timestamps and speaker labels as anchors
A timestamp is a record of the specific minute in the recording when a given statement was made - for example [14:32]. A speaker label is the attribution of that statement to a name or role - for example Emma Taylor (CMO):.
Together, they create what can be called hard informational anchors. When a model cites a passage from a transcription marked this way, it has at its disposal not just the content, but also authorship and location within the source. That transforms a quote from an anonymous claim into a verifiable reference.
In practical terms, these elements significantly reduce the risk of hallucination. A model that has a specific timestamp and an expert's name does not need to interpolate or guess at context - it can invoke the fact precisely. This translates into higher quality generated responses and directly protects the brand against misattribution.
Splitting text into logical segments (chunking)
Chunking is the deliberate division of a long transcription into shorter, thematically coherent chapters. Without this division, a model attempts to process the document as a whole - and frequently loses the thread or cites only passages from the beginning and end.
A useful analogy is a thick encyclopedia: read cover to cover it is impractical, but when divided into individual entries, every question has its own page where an algorithm lands directly. A divided transcription works the same way - each chunk should cover one topic, one Q&A sequence, or one logical argument block.
In practice, a chunk is typically 200 to 500 words. Each segment should open with a heading describing its contents and close at a natural summary point, not mid-thought. This structure allows a model to retrieve a specific answer without processing the entire recording.
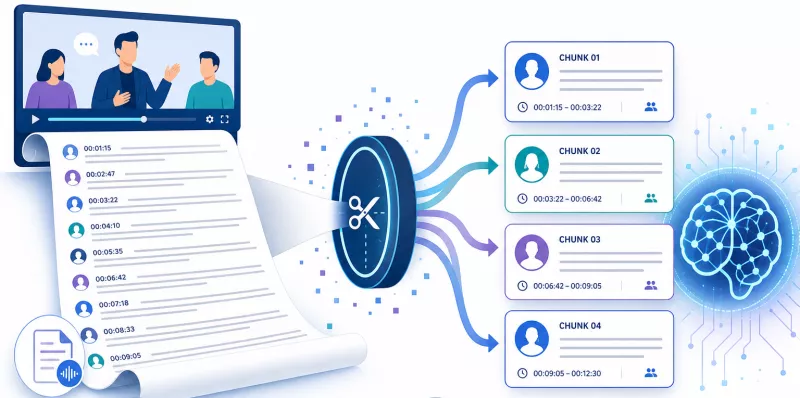
Prompts and phrases that prompt AI to cite the source
Placing specific instructions and patterns in the transcription summary encourages language models to explicitly reference the original video.
Language models learn attribution patterns from the very data they process. If a document consistently uses the formula "according to expert X at minute Y," the model picks up that pattern and reproduces it in generated responses. This is not a citation guarantee - no format provides that certainty - but it is a structural invitation that increases the probability of precise attribution.
The mechanism works because a transcription passage with a clear attribution formula is semantically complete: it contains the claim, the author, and the location within the source. A model retrieving such a passage has everything it needs to cite - and is less likely to reach for alternative, less precise formulations.
English-language attribution patterns to embed in the text
Below are three ready-made attribution patterns worth embedding in section headings, the document introduction, or directly before key statements:
"As explained by Emma Taylor (CMO, Company X) at minute 14:32 of the recording: [quote content]."
"As Oliver Smith indicated during the Q&A session at 31:15, the primary implementation barrier is: [quote content]."
"In response to a participant's question at minute 47:08, expert James Wilson stated: [quote content]."
These patterns operate on several levels simultaneously. Above all, they give the document a reference structure that models recognize as credible. At the same time, they contain all elements required for verification: the expert's name, their role, and the recording timestamp. They should be applied consistently throughout the transcription - particularly before passages that represent the most valuable expert knowledge in a given webinar.
Evaluation prompts for testing webinar visibility
Alongside the patterns embedded in the transcription, it is worth having a set of test prompts the team can use in ChatGPT, Perplexity, or Claude to check whether the webinar is actually being cited. Below are five ready-made prompts:
"What are the most important metrics for measuring brand visibility in AI search? Provide the source, the expert's name, and the recording timestamp if you are drawing on a specific piece of content."
"What do experts say about chunking transcriptions for GEO? Indicate where that information comes from."
"What attribution patterns in webinar transcriptions increase the likelihood of citation by AI models? Provide the author and source."
"How should a webinar transcription be prepared so that ChatGPT or Perplexity cite it as a source? Reference a specific webinar or article if one exists."
"Does the Q&A format in a transcription help AI models generate answers? Provide an example source with the speaker's name and timestamp."
Each of these prompts deliberately includes a request for a source, a name, or a recording timestamp - which makes it possible to assess whether the model is genuinely retrieving information from the prepared transcription or responding in generalities.
Speaker consent and legal safety
Using webinar transcriptions in AI systems requires having clear speaker consent for processing their words for new purposes.
A recording made for a live broadcast does not automatically authorize further processing - transcribing, indexing, and feeding it into AI systems. Every external speaker who participated in a webinar at the organizer's invitation should give explicit consent for those specific uses. The absence of such consent, while simultaneously feeding external tools with other people's statements, is unnecessary business risk and a potential violation of platform terms of service.
The practical solution is simple: before the next webinar, it is worth adding one sentence to the speaker agreement or registration form addressing the use of transcriptions for content marketing and AI systems. For historical archives, a quick review of applicable event terms is recommended, and - where doubt exists - reaching out to participants to confirm consent.
How to measure success and verify brand visibility
The effectiveness of transcription optimization is measured by analyzing citation rate and verifying the precision of responses in AI engines.
The primary measure is citation rate - the frequency with which the brand or a specific webinar appears as a cited source in AI-generated responses to queries within a given topic domain. A complementary metric is citation precision: whether the model is citing the correct claims, attributing them to the correct individuals, and providing accurate timestamps. In working terms, citation precision means the model identified the correct speaker and timestamp; recall means it did so across an appropriate subset of queries, not just for a single prompt.
It is also worth tracking hallucination reduction - the number of instances in which a model incorrectly attributed a claim to a non-existent source or confused authorship. Transcriptions with complete speaker labels should reduce that figure in a measurable way. Ongoing monitoring of model behavior and citation visibility can be effectively automated using SaaS analytics platforms such as BrandInAI.
A simple comparative experiment for the team
A practical A/B test requires no advanced tools. It is enough to select one topic for which the organization has both a standard blog article and a webinar transcription - and then pose a series of complex product-related questions from the same topic domain to an AI model (such as ChatGPT, Perplexity, or Claude).
The experiment protocol is as follows: enter identical, precise queries matching the subject matter of both documents, then observe which format the model draws direct quotes from. The key control questions are: does the model cite a source explicitly, does it invoke an expert's name, and does the cited passage come from the Q&A section or from the narrative portion of the article. For comparable results, all queries should be run within the same time window and using the same pool of questions.
Results are rarely clear-cut after a single iteration - which is why repeating the test with five different queries and recording the proportion of responses in which the transcription "wins" over the article in terms of attribution and citation precision is worthwhile.
Summary and a launch plan: the first pilot
Webinar transcriptions create better conditions for AI citation because they combine three advantages simultaneously: the natural multi-thread quality of expert discussion that mirrors user query patterns, the Q&A format that supplies models with ready knowledge blocks, and the metadata and timestamp structure that makes citation precise and verifiable.
None of these elements works in isolation. A transcription without metadata is difficult to categorize. Metadata without chunking produces documents too long for efficient processing. Chunking without attribution patterns produces quotes with no clear authorship. Only the pipeline combining all four elements - clean text, metadata, speaker labels, and thematic segmentation - creates material that models can treat as a credible reference source.
The recommended pilot involves five webinars: ideally ones covering different topics and containing Q&A sessions. For each, the full pipeline should be run: transcription and correction, a metadata block at the top of the document, speaker labels and timestamps on key statements, division into 200–400-word chunks, and attribution patterns at the most important passages. Then, for each processed webinar, run an A/B test against a blog article from the same topic domain and measure citation rate, attribution precision, and hallucination count.
After four weeks, the pilot should yield enough data to make a decision: which topics generate the highest citation rate, which attribution patterns perform best, and whether the transcription-based article format consistently outperforms the standard blog article. That is a sufficient starting point to decide whether to scale the process across the entire recording archive.